강의 메모 #
카프카 브로커, 클러스터, 주키퍼 #
주키퍼 #
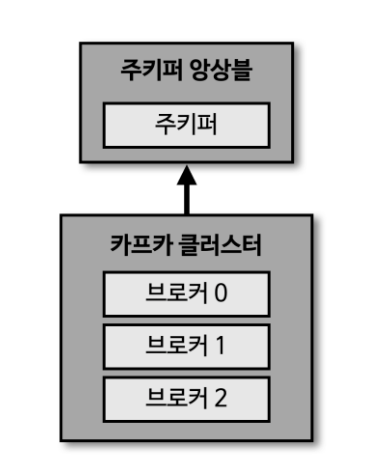 카프카 클러스터를 운영하기 위해 반드시 필요한 애플리케이션
카프카 2.0 버전 까지는 반드시 필요했지만 카프카 3.0부터는 주키퍼가 없더라도 운영됨
아직까지는 주키퍼를 완벽하게 대체하지 못하므로 주키퍼가 있는 카프카 클러스터 운영 기업이 많음
카프카 클러스터를 운영하기 위해 반드시 필요한 애플리케이션
카프카 2.0 버전 까지는 반드시 필요했지만 카프카 3.0부터는 주키퍼가 없더라도 운영됨
아직까지는 주키퍼를 완벽하게 대체하지 못하므로 주키퍼가 있는 카프카 클러스터 운영 기업이 많음
1개의 브로커는 하나의 서버나 인스턴스에서 동작 브로커 3개가 있는 모습
브로커 #
데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 애플리케이션 하나의 서버에는 하나의 카프카 브로커 프로세스가 실행됨 3대 이상의 브로커 서버를 1개의 클러스터로 묶어서 운영한다 카프카 클러스터로 묶인 브로커들은 프로듀서가 보낸 데이터를 안전하게 분산 저장하고 복제하는 역할을 수행한다.
주키퍼 앙상블 #
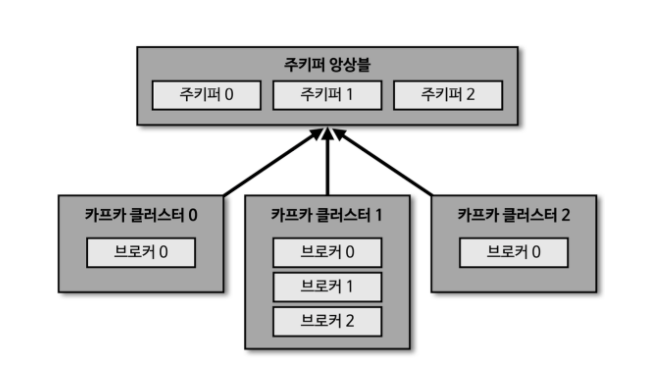
- 카프카 클러스터를 실행하기 위해서는 주키퍼가 필요
- 주키퍼의 서로 다른 znode에 클러스터를 지정
- roor znode에 각 클러스터별 znode를 생성하고 클러스터 실행시 root가 아닌 하위 znode로 설정
- 각 클러스터별로 운영 가능
- 하나의 클러스터별로 주키퍼를 별도로 가져갈 수 있지만, 리소스 낭비가 발생할 수도 있음
- 여러개의 카프카 클러스터를 동시에 운영하는 경우도 있다. ex) 도메인별 등
브로커의 역할 - 컨트롤러, 데이터 삭제 #
컨트롤러 #
다수 브로커 중 1대가 컨트롤러 역할함
- 다른 브로커들의 상태 체크
- 이슈가 발생하면 해당 브로커에 존재하는 리더 파티션을 재분배 여러대의 브로커 중 이슈가 발생했을때 장애가 발생한 브로커를 제외하고, 여기에 원래 있던 리더 파티션을 재분배 카프카는 지속적으로 데이터를 처리해야하기 때문에 비정상인 브로커를 빠르게 클러스터에서 제외시켜야한다 리더 파티션을 빠르게 팔로워 파티션이 승급받아서 다시 정상 운영되어야함 다른 브로커가 컨트롤러 역할을 하고 다시 리더 파티션의 데이터를 분배한다
데이터 삭제 #
브로커가 로그 세그먼트(log segment) 단위로 데이터를 삭제한다. 일정시간, 용량에 따라서 데이터 삭제 수행 compact 옵션으로 특수한 상황에서 가장 최신의 key가 있는 레코드를 제외하고 나머지 레코드들을 삭제 수행할 수 있음
컨슈머 오프셋 저장 #
컨슈머 그룹은 토픽이 특정 파티션으로부터 데이터를 가져가서 처리하고, 이 파티션의 어느 레코드까지 가져갔는지 확인하기 위해 오프셋을 커밋한다 _consumer_offsets 토픽에 저장 (internal 토픽) 여기에 저장된 오프셋을 토대로 컨슈머 그룹은 다음 레코드를 가져가서 처리한다.
그룹 코디네이터 #
컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 분배하는 역할을 한다. 컨슈머가 컨슈머 그룹에서 빠지면 매칭되지 않은 파티션을 정상 동작하는 컨슈머로 할당하여 끊임없이 데이터가 처리되도록 도와준다. 문제가 있는 컨슈머를 삭제하고 다시 파티션을 컨슈머로 재할당하는 과정 : 리밸런드(rebalance)
데이터의 저장 #
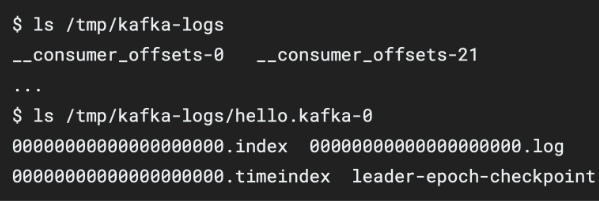
conifg/server.properties의 log.dir 옵션에 정의한 디렉토리에 데이터를 저장 (파일 시스템) 토픽 이름과 파티션 번호의 조합으로 하위 디렉토리를 생성하여 데이터를 저장