내가 만든 서비스는 얼마나 많은 사용자가 이용할 수 있을까? #
성능 테스트는 왜 해야 할까? #
- 성능 테스트 : 서비스의 성능적인 부분을 측정하기 위해 실행되는 작업
- 애플리케이션의 성능을 측정 : 점진적인 부하를 가하는 과정 속에서 더 이상 처리량이 증가하지 않을 때, 그 수치를 측정하고 해석하는 것
- 목적
-
- 현재 애플리케이션이 최대 몇 명의 사용자를 수용할 수 있는지 측정하고, 그 결과가 최초 목표한 성능에 부합하는지 알아내기 위함
-
- 목표 성능에 부합하지 않는다면 어떤 지점에서 병목이 발생하고, 이를 해결하기 위해 무엇을 해야 하는지 분석하여 개선함으로써 최종적으로 서비스가 중단되는 상황 없이 제공될 수 있도록 가용성을 높이는 것
-
서비스가 빠른지 느린지 어떻게 알 수 있을까? #
- Throughput : 시간당 처리량
- TPS(Transaction Per Second), RPS(Request Per Second) 등으로도 불리며, ‘1초에 처리하는 단위 작업의 수’ 혹은 ‘1초에 처리하는 HTTP 요청 수’ 등으로 해석
- 1초에 최대한 많은 작업을 처리할 수 있는 서비스가 성능 측면에서 좋은 서비스라고 볼 수 있다.
- ex) A 서비스는 1초에 1000개의 작업을 처리하고 B 서비스는 1초에 2000개의 작업을 처리할 수 있는 능력을 가졌다면 B 서비스가 동일 시간 내에 더 많은 작업을 할 수 있으므로 성능면에서 더 좋다고 볼 수 있다.
- Throughput을 보면 내 서비스의 작업 처리 능력을 알 수 있으며, 이는 서비스 성능의 지표가 될 수 있다.
- Latency : 서버가 클라이언트로부터 요청을 받아서 응답을 보내주기까지 걸리는 시간을 의미
- 서비스가 작업을 얼마나 빠르게 처리할 수 있는지를 나타내는 성능 지표
- 서버가 클라이언트의 요청을 처리하는데 발생하는 지연시간으로도 생각해볼 수 있다.
- ex) A 서비스의 웹 서버가 WAS로부터 요청을 응답을 보내는데 걸리는 시간이 100㎳이고, B 서비스의 WAS가 동일 작업을 처리하는데 50㎳가 걸렸다면 B 서비스가 작업을 더 빨리 처리할 수 있음을 알 수 있고, 이에 따라 성능면에서 더 좋다고 볼 수 있다.
서비스 성능에 대한 기준이 생겼으니, 기준에 따라 해석하고 개선해보기 #
웹 서버 - WAS - DB로 구성된 서비스를 예로 살펴보자.
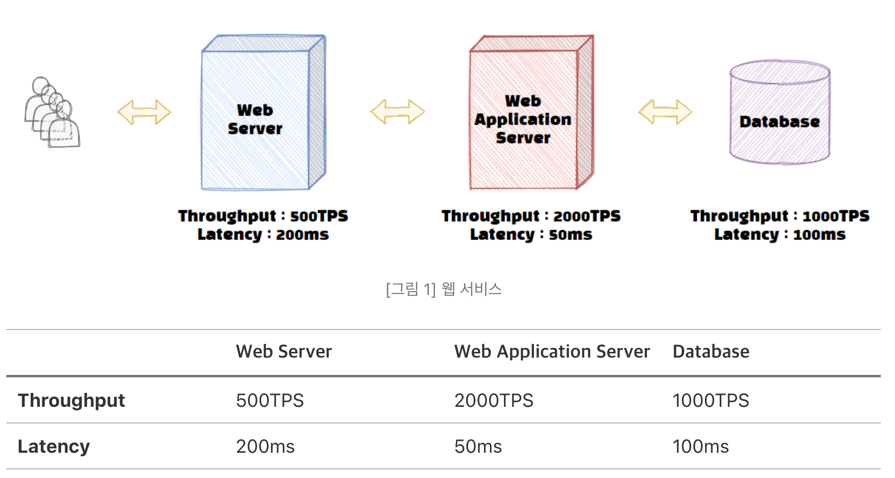
전체 서비스의 Throughput은 얼마나 될까? 500 TPS
성능에 대한 비유는 흔히 고속도로 정체 상황을 비유한다. 하나의 작업을 차 한 대로 가정하고, 500 TPS는 Web 서버라는 고속도로를 1시간당 500대의 차가 통과한다고 가정해보자. 이러한 상황에서 만약에 2000대의 차량이 해당 도로를 통과하면 어떤 일이 벌어질까? 총 TPS의 합이 3500 TPS이니까 모든 도로가 원활하게 차를 수용할 수 있을까? 역시 불가능합니다. Web 서버에서 차들은 정체되고, WAS와 데이터베이스는 Web 서버를 통과한 차들만 수용할 수 있으므로 아무리 시간당 1000대, 2000대를 통과시킬 수 있는 수용력이 있어도 결국에는 시간당 500대만 통과하게 된다. 현재 상황을 웹 서비스로 다시 돌아와 보면 이러한 경우, 웹 서버에서 병목이 발생했다고 볼 수 있다.
여기서 DB나 WAS 성능을 아래와 같이 개선한다고 해서 전체 서비스의 성능이 올라갈까?
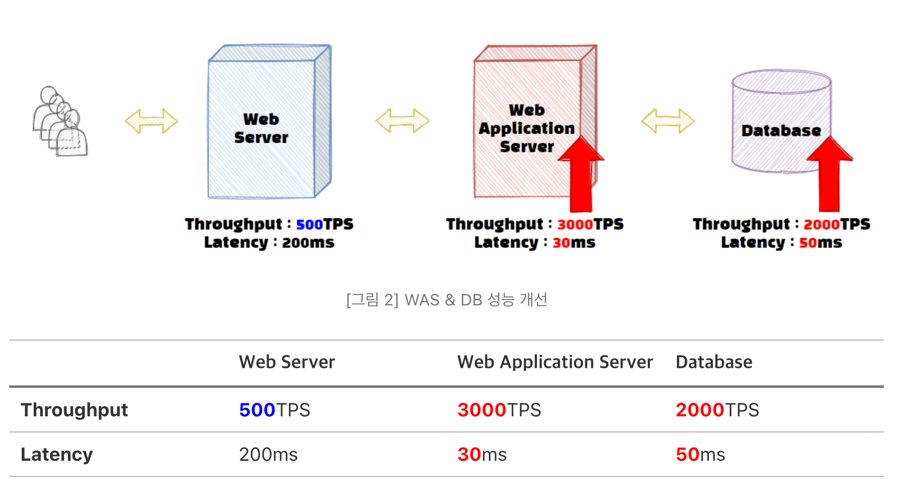
Web 서버의 Throughput은 500 TPS로 동일하기 때문에 해당 서비스는 여전히 초당 500개의 트랜잭션만 통과할 수 있다. 이러한 병목 현상과 같이 서비스의 성능 중 가장 큰 영향을 미치는 부분을 Critical Path라고 한다. 서비스의 전체 성능을 높이기 위해서는 (병목을) Critical Path를 찾아야 하고, 여기에 해당하는 Throughput이 증가해야만 해결할 수 있다.
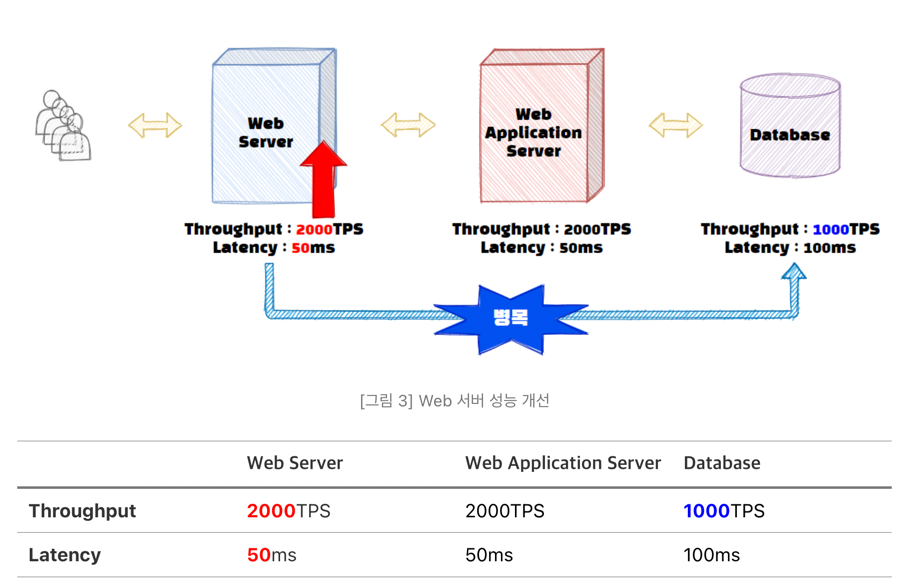
다시 돌아와서 데이터베이스와 WAS는 그대로 두고 Web 서버의 성능을 개선해보자.
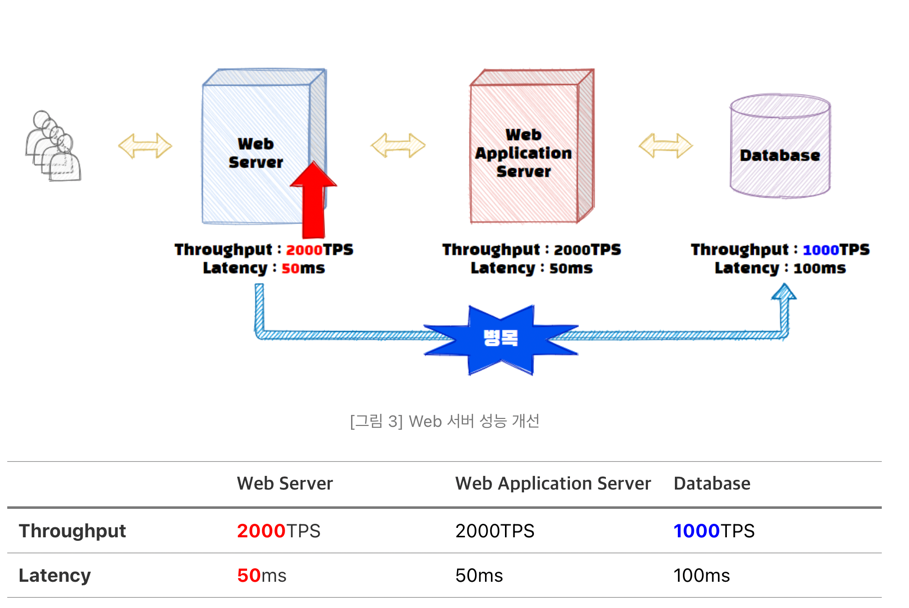
그림을 보면 Web서버의 Throughput이 개선되자 Web서버와 WAS에서는 2000개의 트랜잭션을 처리할 수 있게 되었다. 하지만 데이터베이스에서는 초당 2000개의 처리 작업을 수행할 수 없으니, 서비스 전체의 Throughput은 데이터베이스의 Throughput인 1000 TPS로 변경되었다. 그래도 이전 500 TPS에서 1000 TPS로 Throughput이 개선되었으니 해당 서비스의 성능은 2배 빨라졌다고 할 수 있다.
또한 병목이 Web서버에서 데이터베이스로 옮겨갔죠? 이와 같이 기존 구간의 성능 개선을 하게 되면 Critical Path는 이동하게 되고, 우리는 이러한 병목 구간을 Critical Path를 지속적으로 해결하면서 전체 서비스의 성능을 올려야만 한다.
종합해보면 우리가 서비스의 Throughput이라고 말하는 것은 서비스의 하위 시스템들 중 가장 낮은 처리량을 의미한다. 또한 Throughput 관점에서 성능을 개선한다는 의미는 Critical Path를 찾아서 이를 개선하는 것이라고 할 수 있다.
다음으로 서비스의 Latency는 얼마일까?
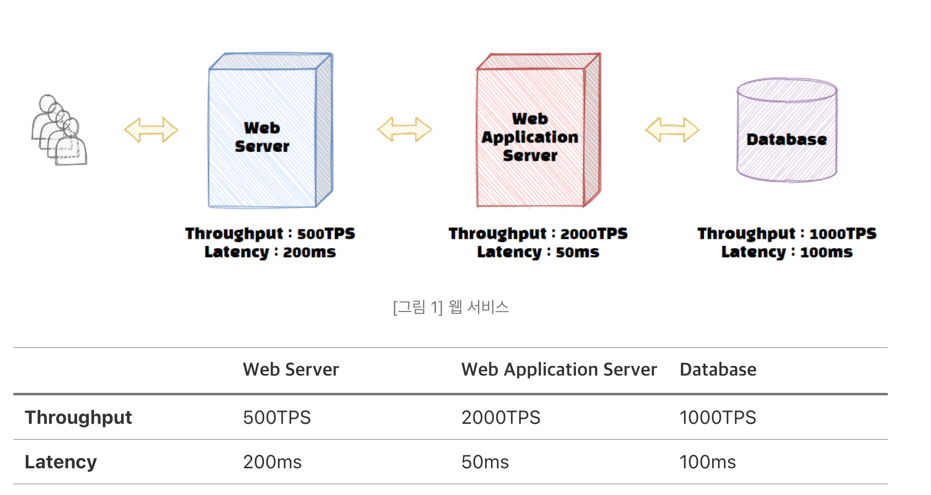
서비스의 Latency는 대기시간을 포함한 각 하위 시스템 Latency의 총합이다. [그림 1]을 다시 참고하면 현재 서비스의 Latency는 ‘350ms + 대기시간’으로 해석할 수 있다.
Latency를 개선하기 위해서 고려할 요소들은 굉장히 많다. 기본적으로 하드웨어의 처리 성능, 애플리케이션 로직, 쿼리 인덱스 등 다양한 원인으로 작업의 Latency가 발생할 수 있다. 더 나아가 Throughput이 한계점에 도달하면 대기시간 또한 길어지므로 Latency 발생의 원인이 될 수 있다.
Throughput을 분석할 때와 달리 Latency의 경우, 하나의 하위 시스템 Latency가 줄어들면 전체 서비스의 Latency도 줄어들게 되므로 병목 구간을 찾기보다 가장 Latency가 큰 하위 시스템을 개선하는 것이 서비스의 Latency를 큰 폭으로 줄일 수 있는 방법이다.
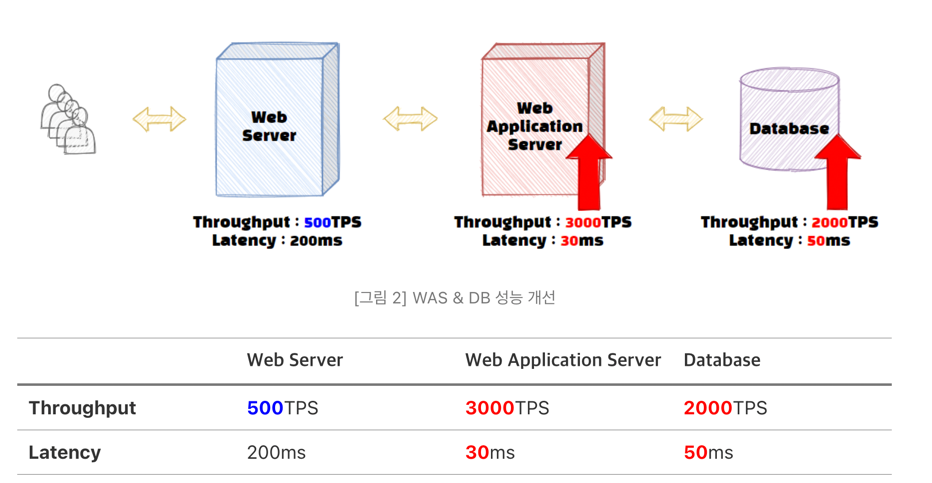
[그림 2]의 경우, 병목 구간이 그대로 이기 때문에 Throughput은 개선 전과 동일했지만 Latency는 WAS 20ms + 데이터베이스 50ms = 70ms 줄어들어서 전체 서비스의 대기시간을 제외한 Latency가 ‘350ms’에서 ‘280ms’로 줄어드는 것을 확인할 수 있다. 이렇듯 서비스 Latency 개선의 경우, 병목 지점과 관계없이 각 하위 시스템들의 Latency 개선이 전부 영향을 줄 수 있음을 알 수 있다.
Throughput을 개선하면 대기시간이 줄어들어 Latency를 줄일 수 있다. Throughput을 개선하는 것이 Latency 개선에도 영향을 줄 수 있다.
결론 #
- 성능 테스트는 서비스가 목표하는 최대 사용자 수에 도달하기 위해 현재 성능을 파악하고, 개선하는 작업이다.
- 서비스의 성능을 알 수 있는 지표는 Throughput과 Latency가 있다.
- 전체 서비스의 성능을 개선하기 위해서는 하위 시스템의 병목 구간을 Critical Path를 찾아 개선하여 Throughput이 증가해야만 하고, 각 하위 시스템의 Latency를 줄여서 전체 서비스의 Latency를 줄여야만 한다.
TPS #
- 지표 예시 : Whatap Application TPS Metric
TPS 계산 #
- Transaction Per Second(TPS) : 초당 트랜잭션의 개수이다.
- 실제 계산하는 방식 : 일정 기간 동안 실행된 트랜잭션의 개수를 구하고 다시 1초 구간에 대한 값으로 변경한다.
- 위 이미지인 와탭의 경우 : 5초 구간으로 값을 수집하기 때문에 단위시간 동안 집계된 트랜잭션의 수를 5로 나눈 값이 표시된다.
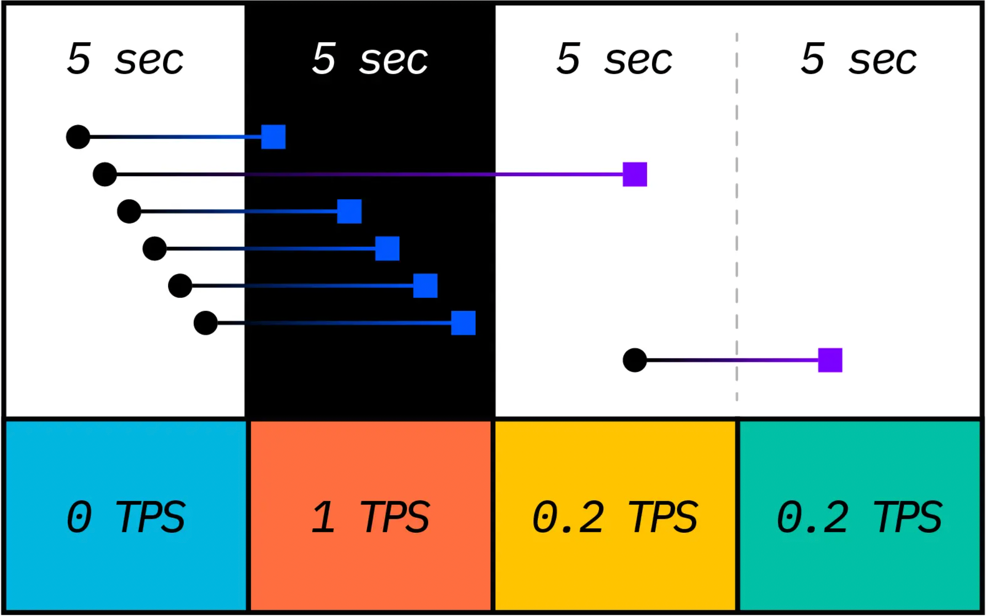 위에 그림에 두 번째 열을 보면 5개의 트랜잭션이 실행 완료된 것을 볼 수 있다.
이런 경우 TPS를 구하는 방법은
위에 그림에 두 번째 열을 보면 5개의 트랜잭션이 실행 완료된 것을 볼 수 있다.
이런 경우 TPS를 구하는 방법은 5 transaction / 5 sec이므로 결과값은 1 TPS가 된다.
(와탭의 TPS 지표는 좀 더 복잡하게 계산한다. 와탭은 차트의 추세를 보여주기 위해 5초 간격으로 30초 평균 TPS를 보여주고 있다.)
Saturation Point 와 TPS가 낮은 이유 #
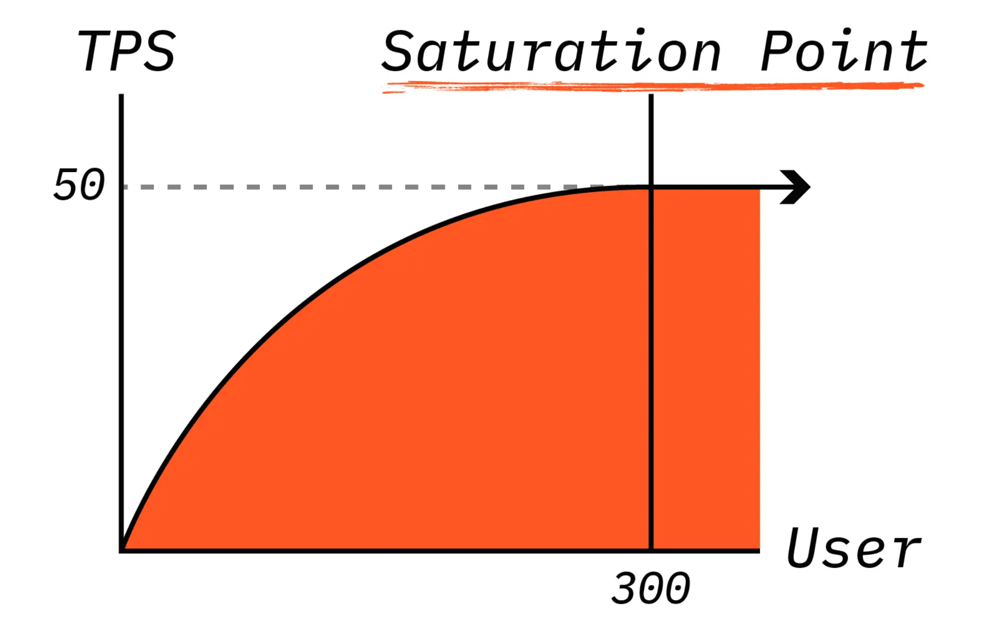
서비스에 사용자가 지속적으로 늘어나면 어느 순간부터 TPS가 더 이상 증가하지 않는 상황이 발생한다.
이렇게 증가하지 않는 지점을 Saturation Point라고 한다.
위 그림은 서비스가 이상적인 상황이다.
제대로 튜닝이 되지 않은 서비스는 Saturation Point를 지나면 오히려 TPS가 떨어지기도 한다.
위 글로 보면 서비스 사용자는 300명이 넘어가면 TPS가 고정되면서 상대적으로 트랜잭션의 응답시간이 길어질 것을 예상할 수 있다.
위 그림을 보면 동시 접속 사용자가 300명이 넘어가면 TPS는 더 이상 올라가지 않으므로 서비스의 정체 시간은 증가하기 시작한다. 300명의 요청사항에 대한 TPS가 50이라면 해당 요청 사항을 다 처리하는데 6초가 걸린다고 생각할 수 있다. 이렇게 TPS와 동시 접속자를 미리 선정해봄으로써 서비스의 성능을 상상해 볼 수 있다.
TPS 요약 #
- TPS는 초당 트랜잭션의 개수를 말한다.
- TPS는 서비스 성능의 기준이 된다.
- 평소 TPS 지표를 체크하자. TPS를 통해 무슨 요일에 또는 몇시에 최대치가 되는지 확인해야한다.
- TPS가 더 이상 증가하지 않은 지점을 Saturation Point라고 한다.
- Saturation Point가 넘으면서 사용자가 몰리면 TPS가 고정된 상태에서 응답시간이 길어지게 된다.