[Youtube 세미나 보기] Batch Performance 극한으로 끌어올리기: 1억 건 데이터 처리를 위한 노력 / if(kakao)2022 #
다루고자 하는 내용 #
- 개발자들은 언제 Batch를 개발할까?
- 특정 시간에 많은 데이터를 일괄 처리

- 특정 시간에 많은 데이터를 일괄 처리
- 배치를 사용하는 상황
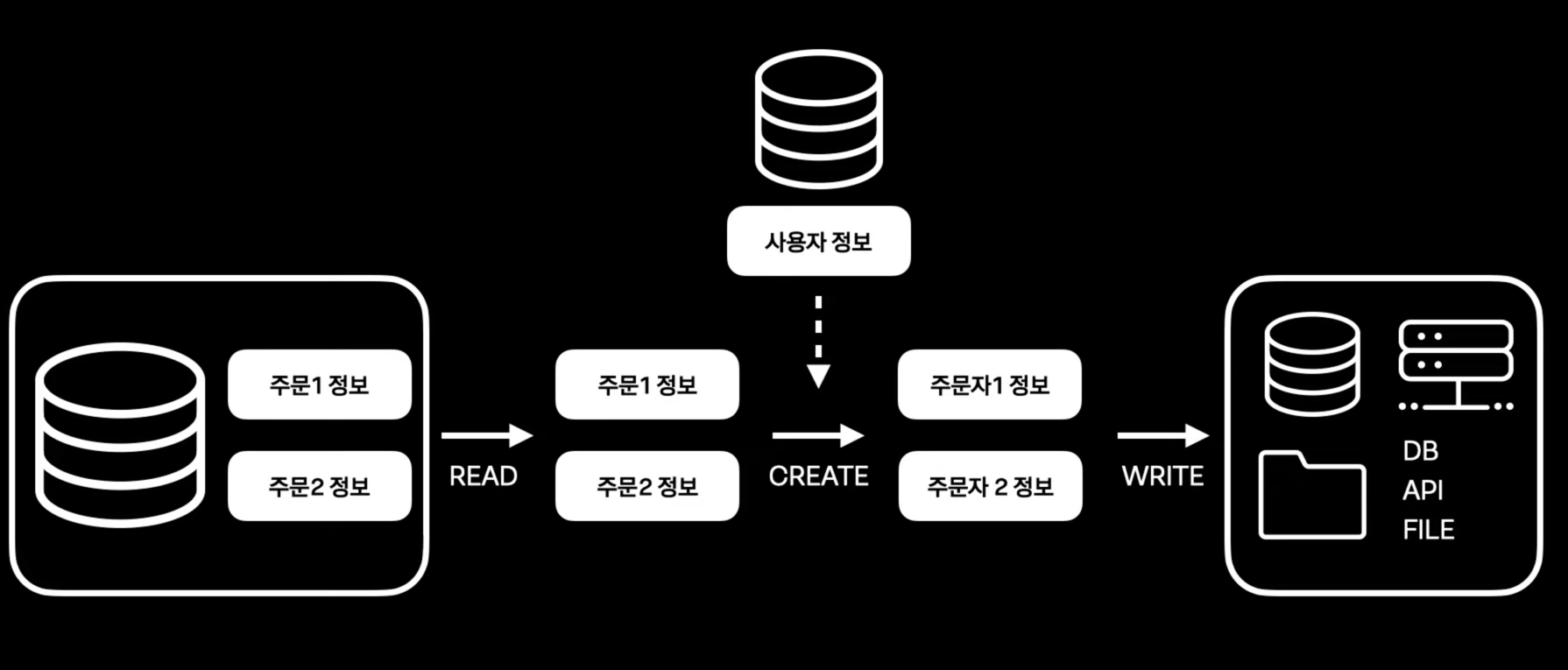
- 일괄 생성
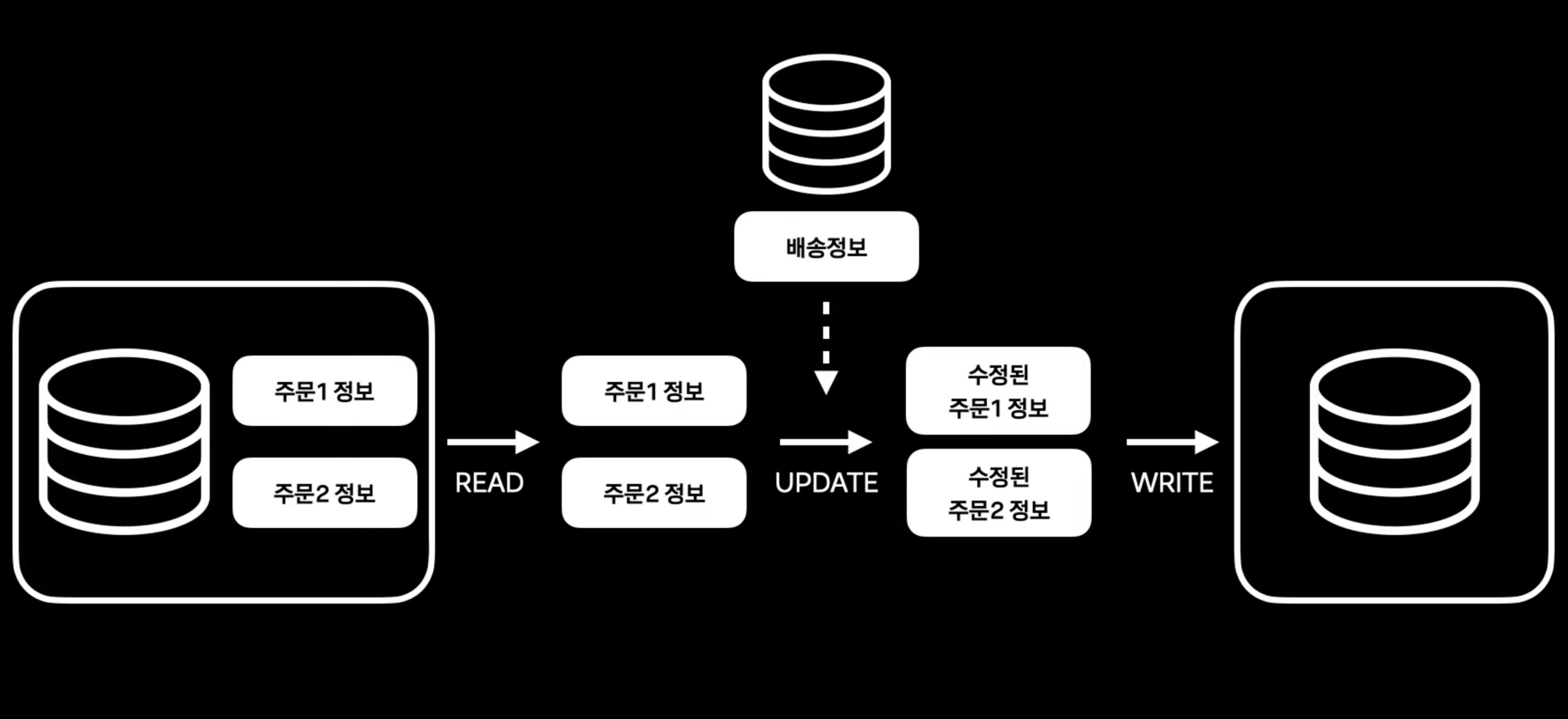
- 일괄 수정
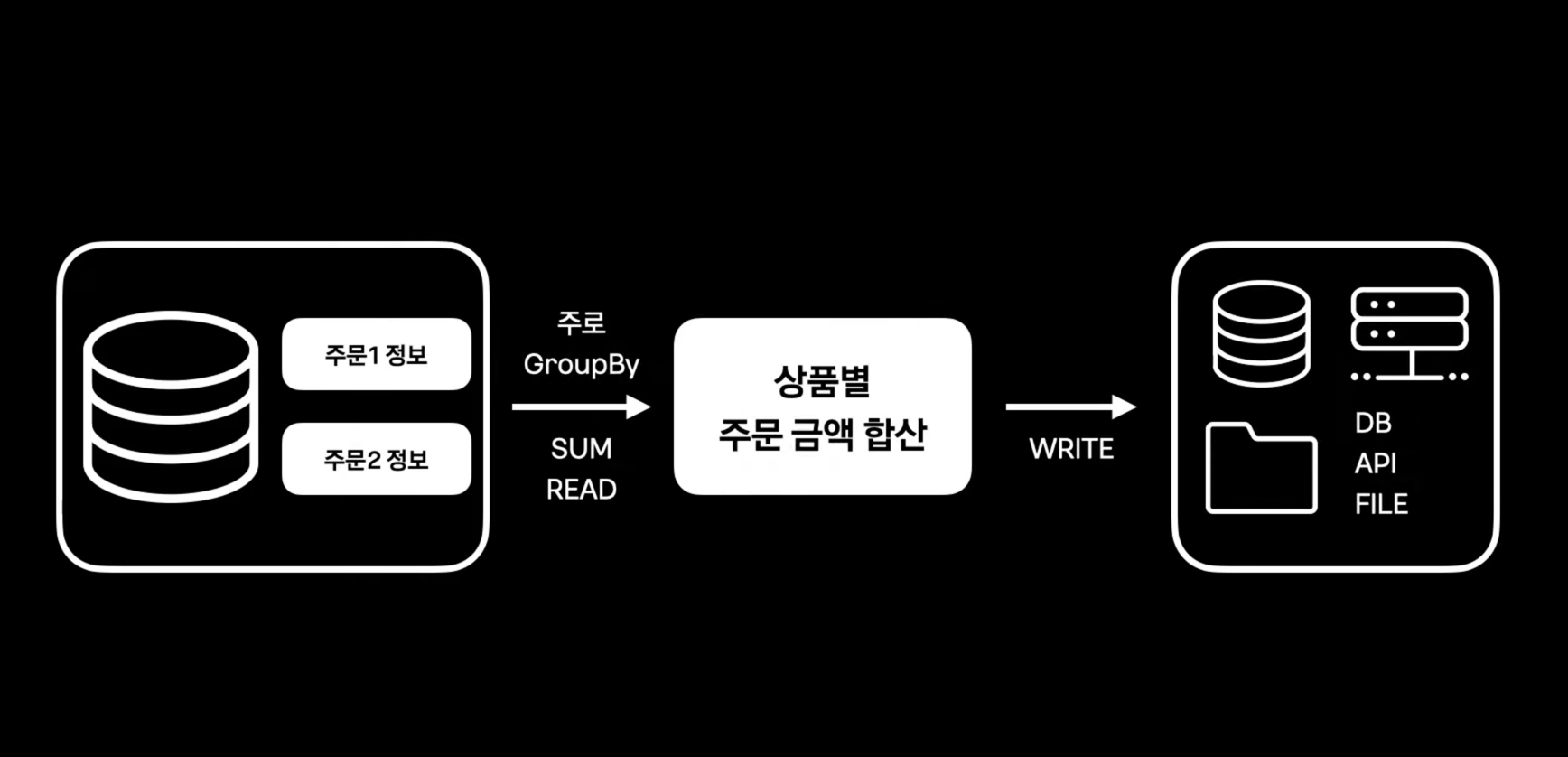
- 통계
- 일괄 생성
무관심한 Batch Performance #

- Batch 개발을 쉽게 생각하는 경향
- 배포후 관리 소홀
- 배치를 지원하는 APM Tool의 부재
많은 데이터 처리량 #
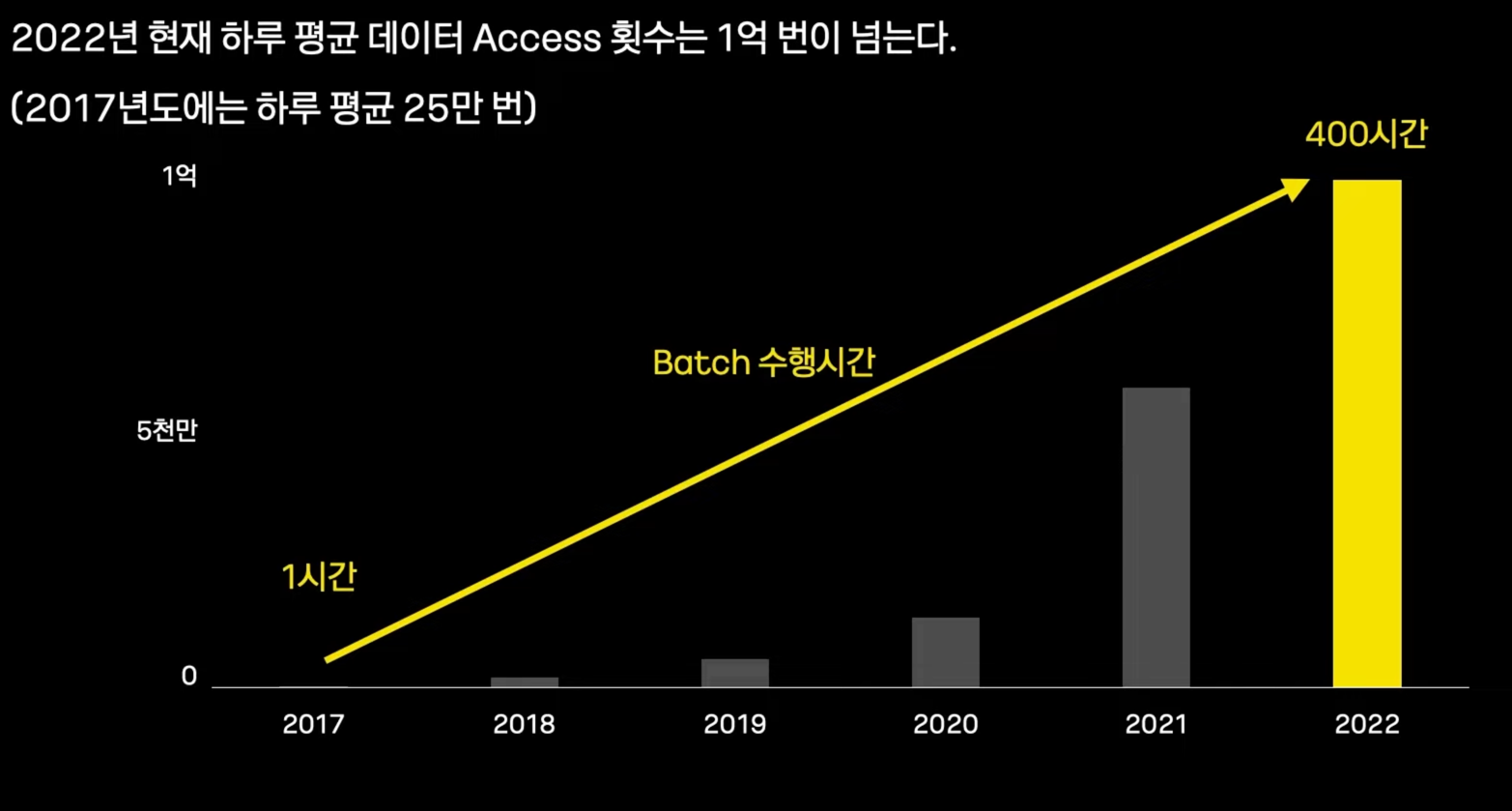
- 2017년 : 하루 평균 25만번
- 현재 : 1억번
- 그럼에도 Batch 수행시간은 1시간으로 동일하다.
어떻게 Batch Performance 개선이 가능했을까? #
- Batch 처리의 순수한 성능 개선 관점
- 대량 데이터 처리 Batch 개발자를 위함
개발 환경 #

효과적인 대량 데이터 Reader 개선 #
- Batch 성능에서 차지하는 비중은 Reader > Writer
- Reader의 복잡한 조회 조건

- 대부분의 상황은 아래와 같이, 필요한 데이터만 골라내야한다.
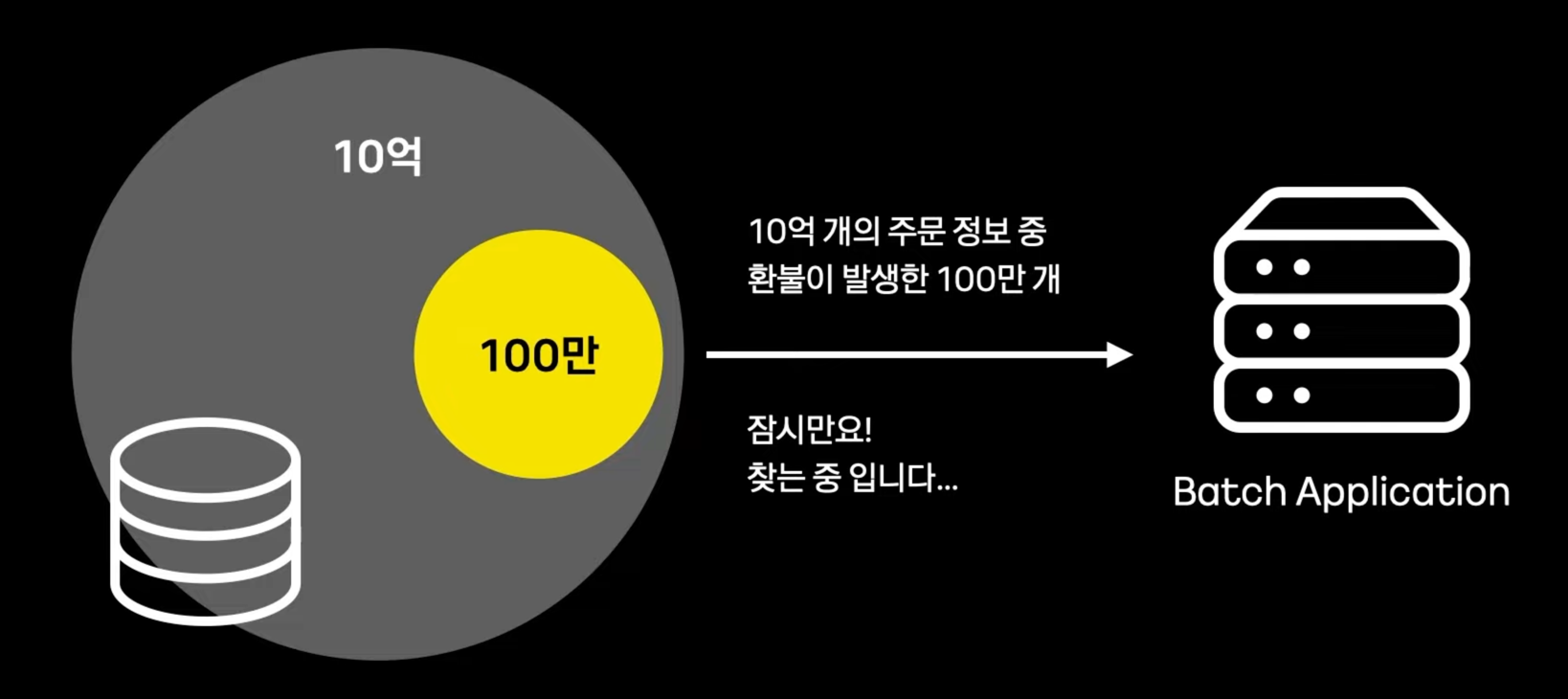
- 대부분의 상황은 아래와 같이, 필요한 데이터만 골라내야한다.
Batch에서 데이터를 읽는 절대적인 방법 - Chunk Processing #
- 1000만개의 데이터를 한번에 처리 가능한 application은 거의 없다.
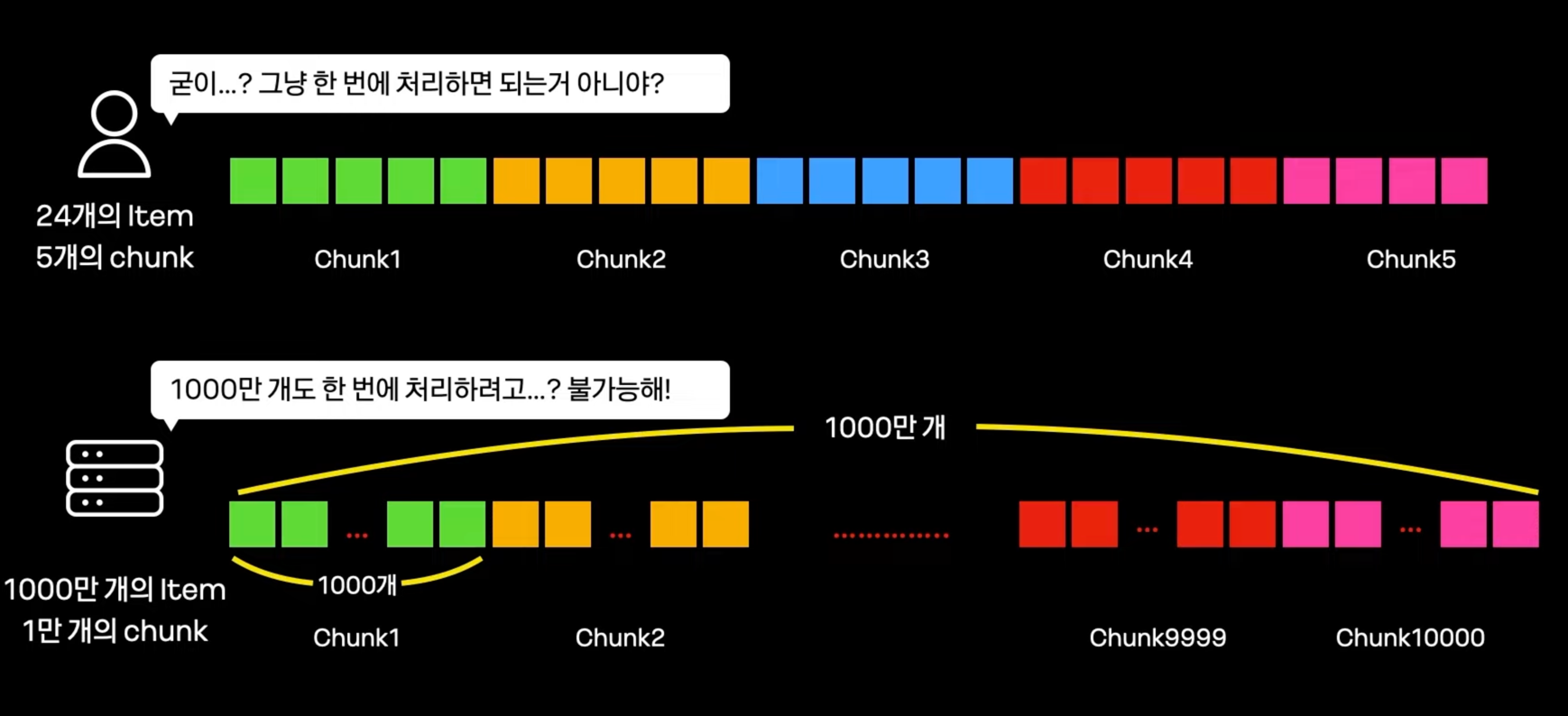
- 나누어 처리하는 방식 : chunk Processing
- Pagination Reader
- 데이터를 한번에 받지 않고, Page 단위로 받음
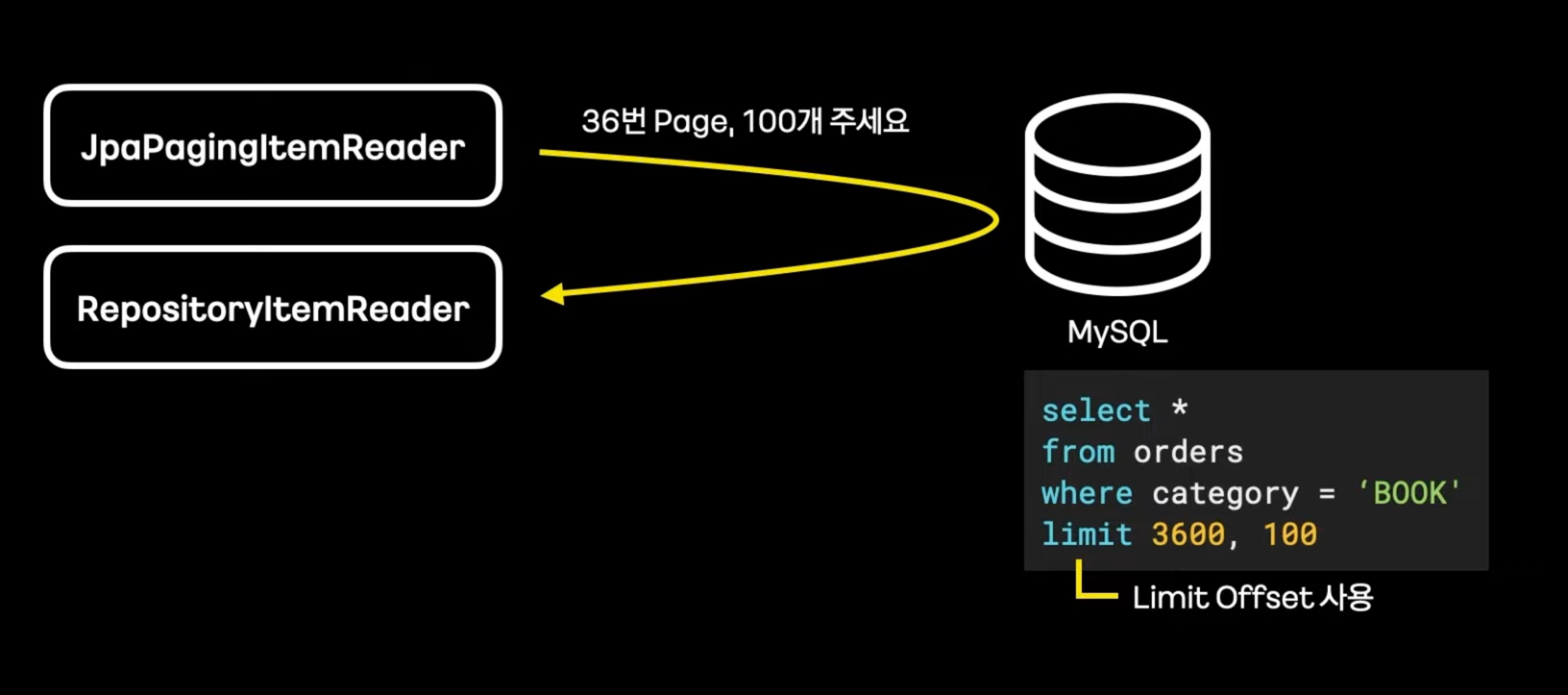
- 이런 방식은 대량 처리에 매우 부적합하다.
- Limit Offset이 가지는 태생적인 한계 때문이다. Offset이 커질수록 느려진다. (mysql이 5000000번째 데이터 찾는것에 상당한 부담을 느낀다.)
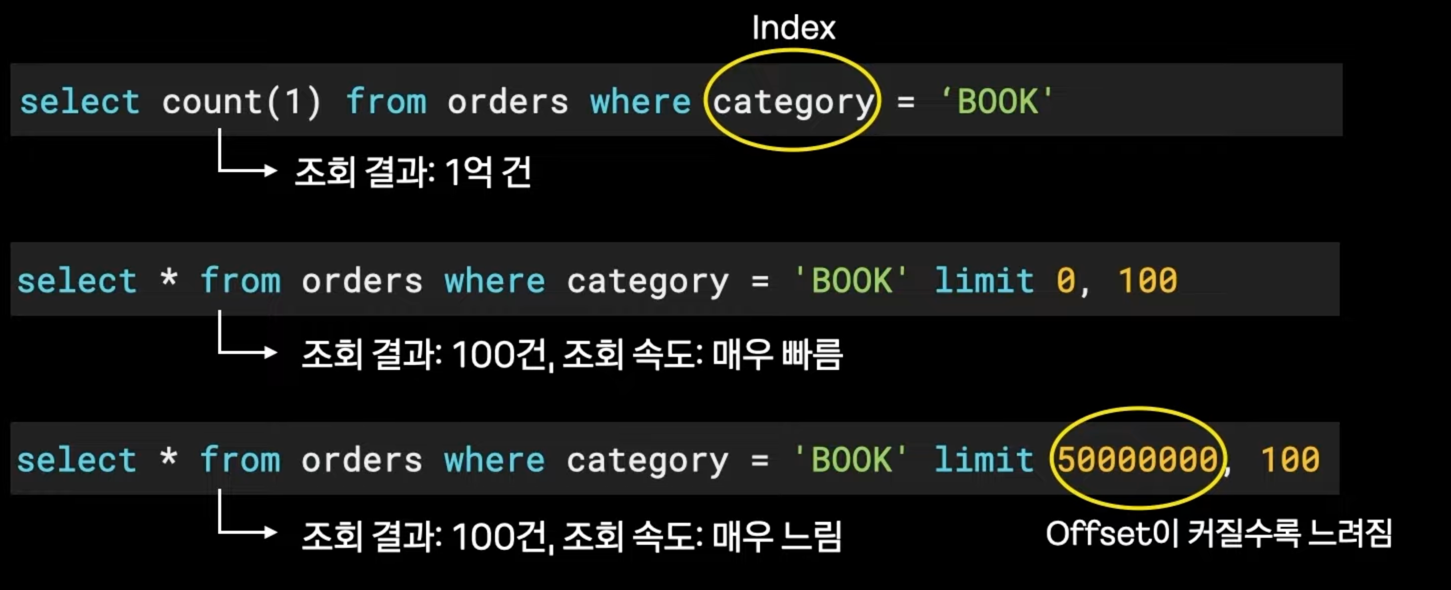
- 데이터를 한번에 받지 않고, Page 단위로 받음
- 위 문제를 해결한 Reader : ZeroOffsetItemReader (항상 offset을 0으로 유지한다.)
-
- PK를 기준으로 오름차순 정렬
-
- 생성한 쿼리에 자동으로 PK 조건을 추가해서 offset을 0으로 유지한다.
-
- 3번째 page는 2번째의 마지막 id보다 +1로 두면 된다.
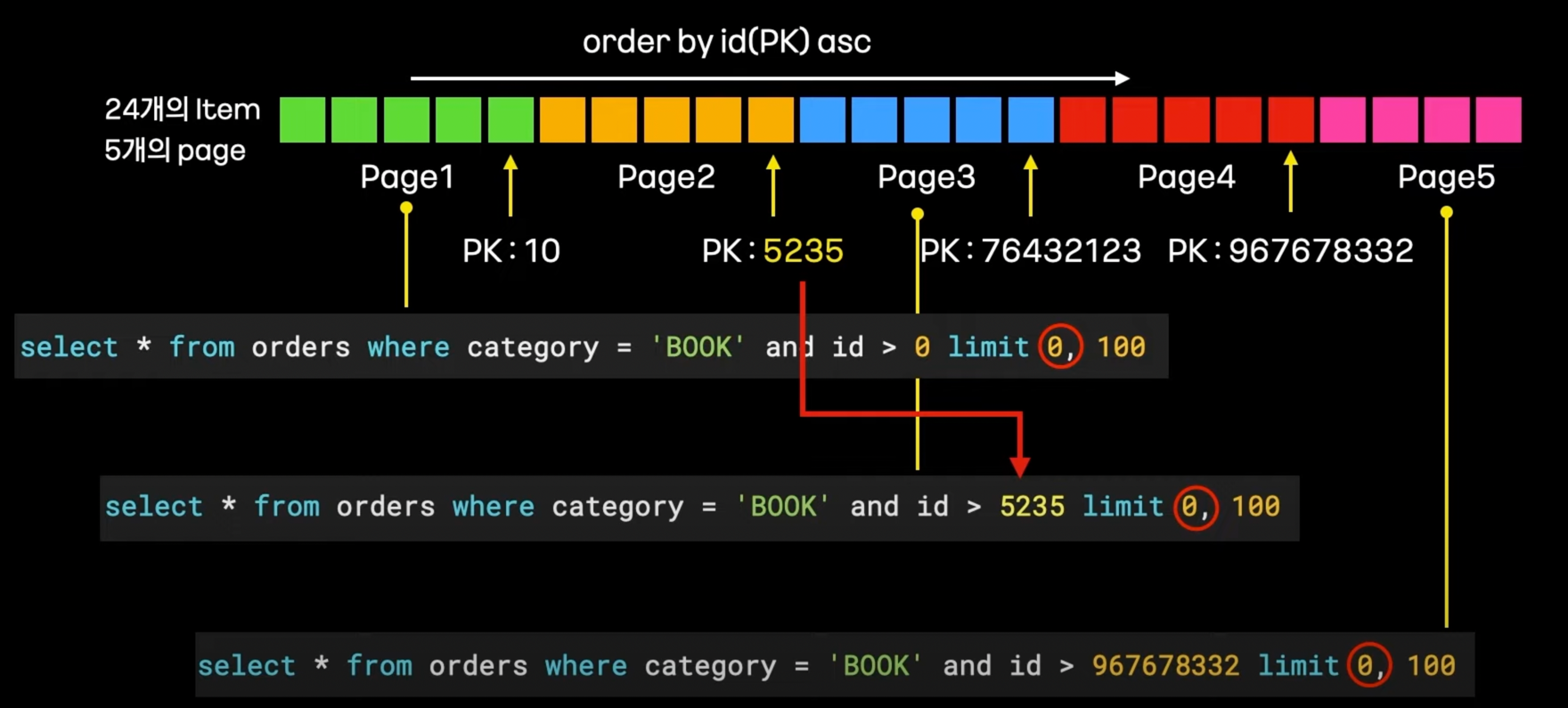
- 3번째 page는 2번째의 마지막 id보다 +1로 두면 된다.
-
- 추가적으로 QueryDSL 적용 (Query Domain Specific Language)
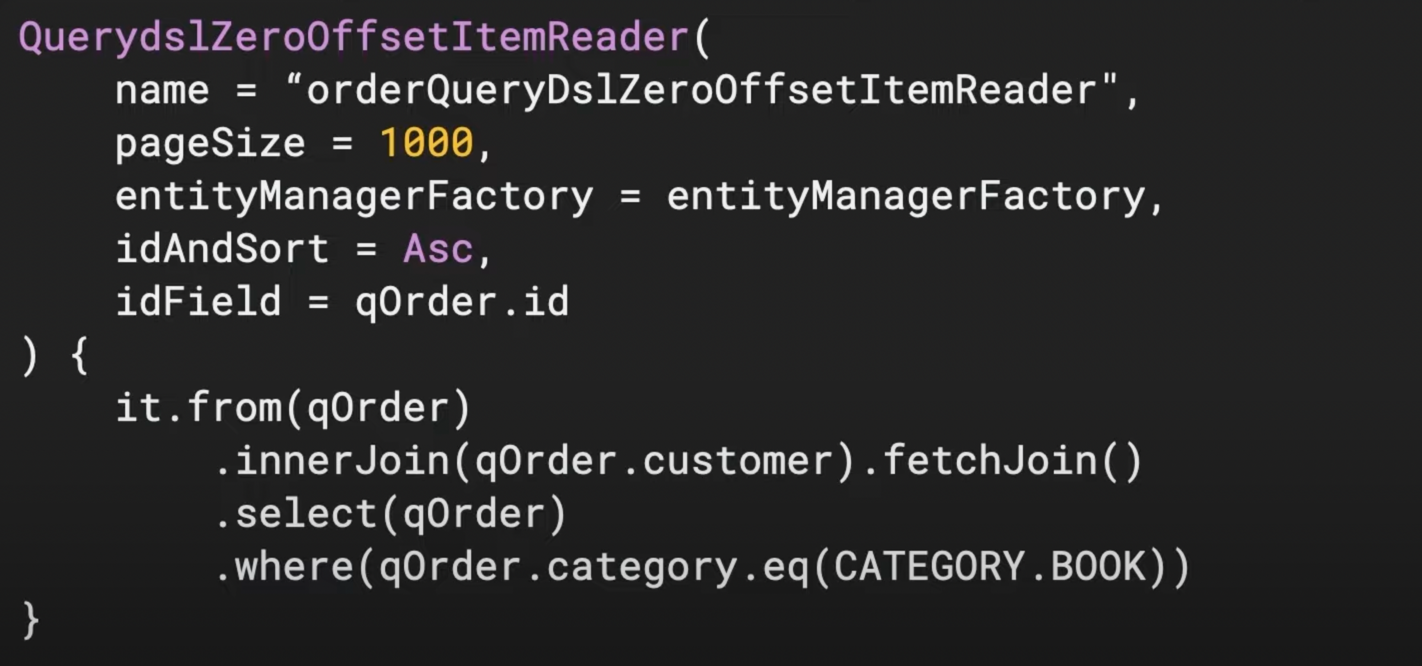
다른 해결방안- Cursor을 사용하자. #
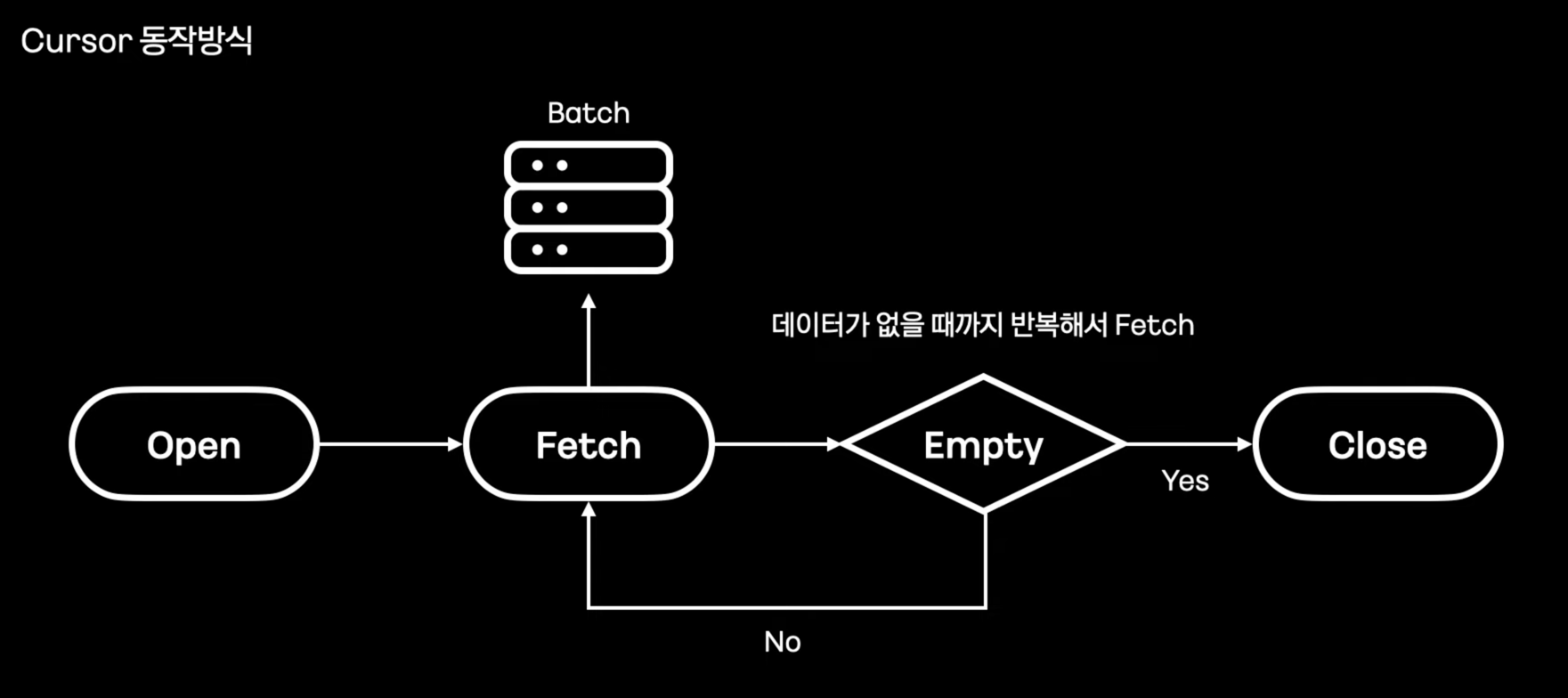

- JpaCursorItemReader은 OOM 발생 가능성이 있다.
- 더 안전항 방식은?
- Exposed 사용
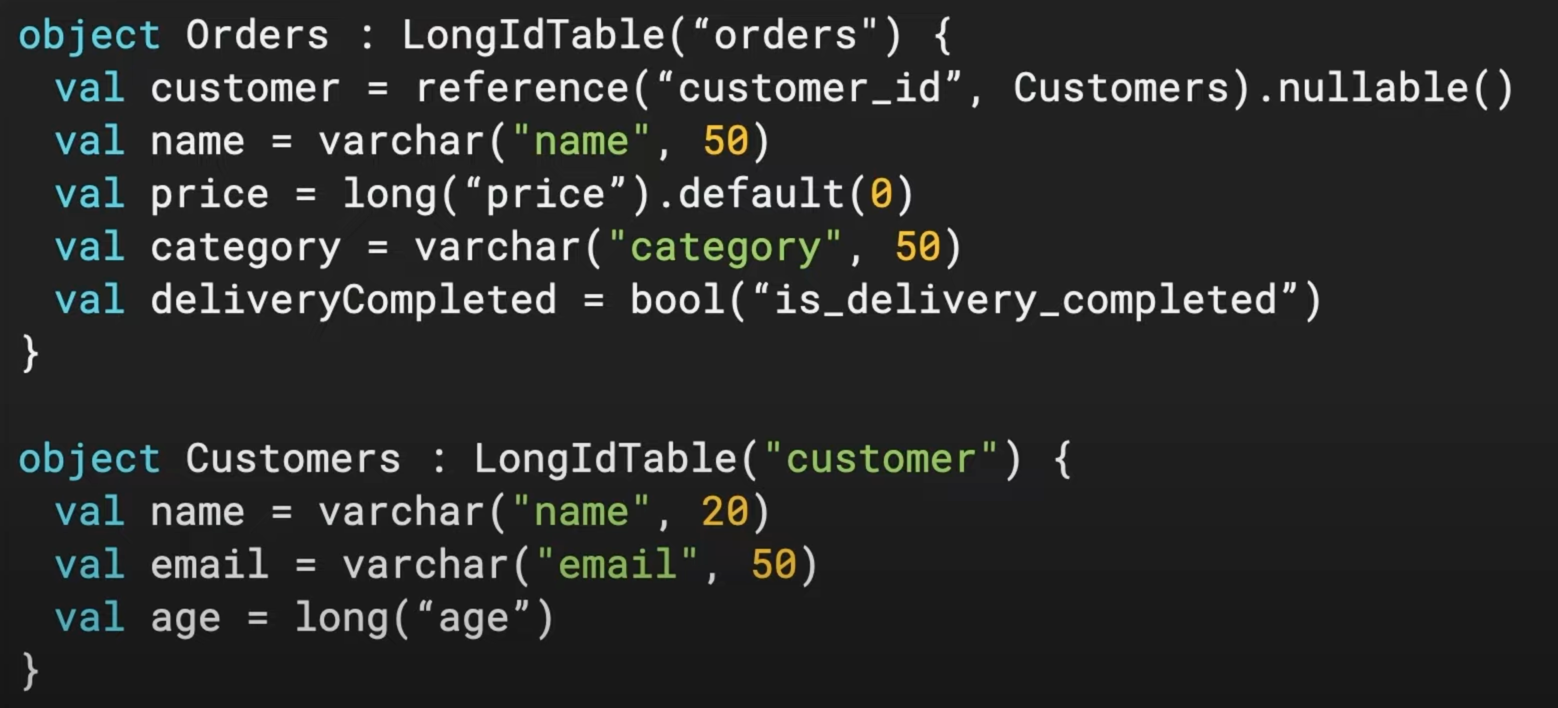
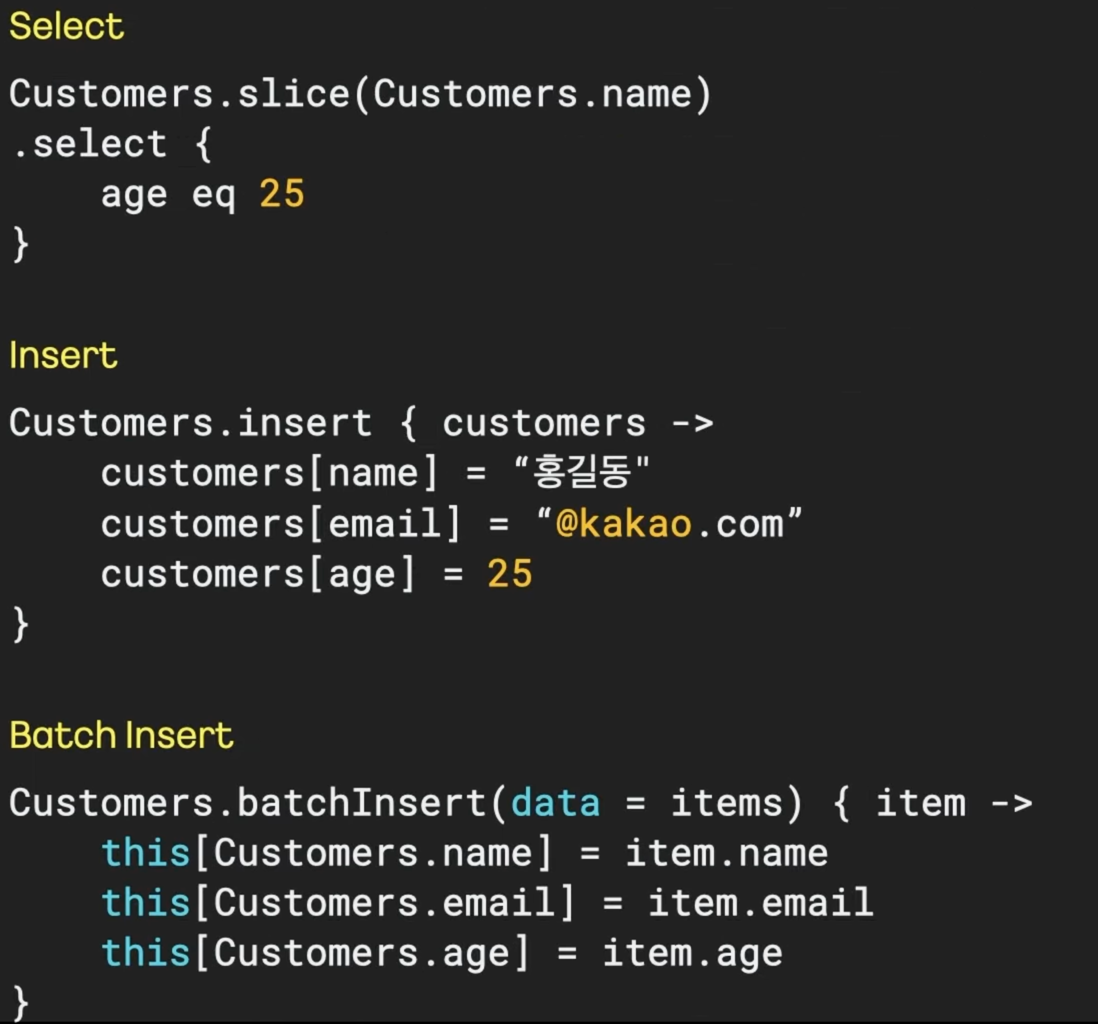
새로운 방식의 쿼리 구현, Exposed #

- Exposed DSL 도입 이유: Kotlin 언어적 특성을 활용해서 세련되게 쿼리를 구현 가능
얼마나 개선되었을까? #
-
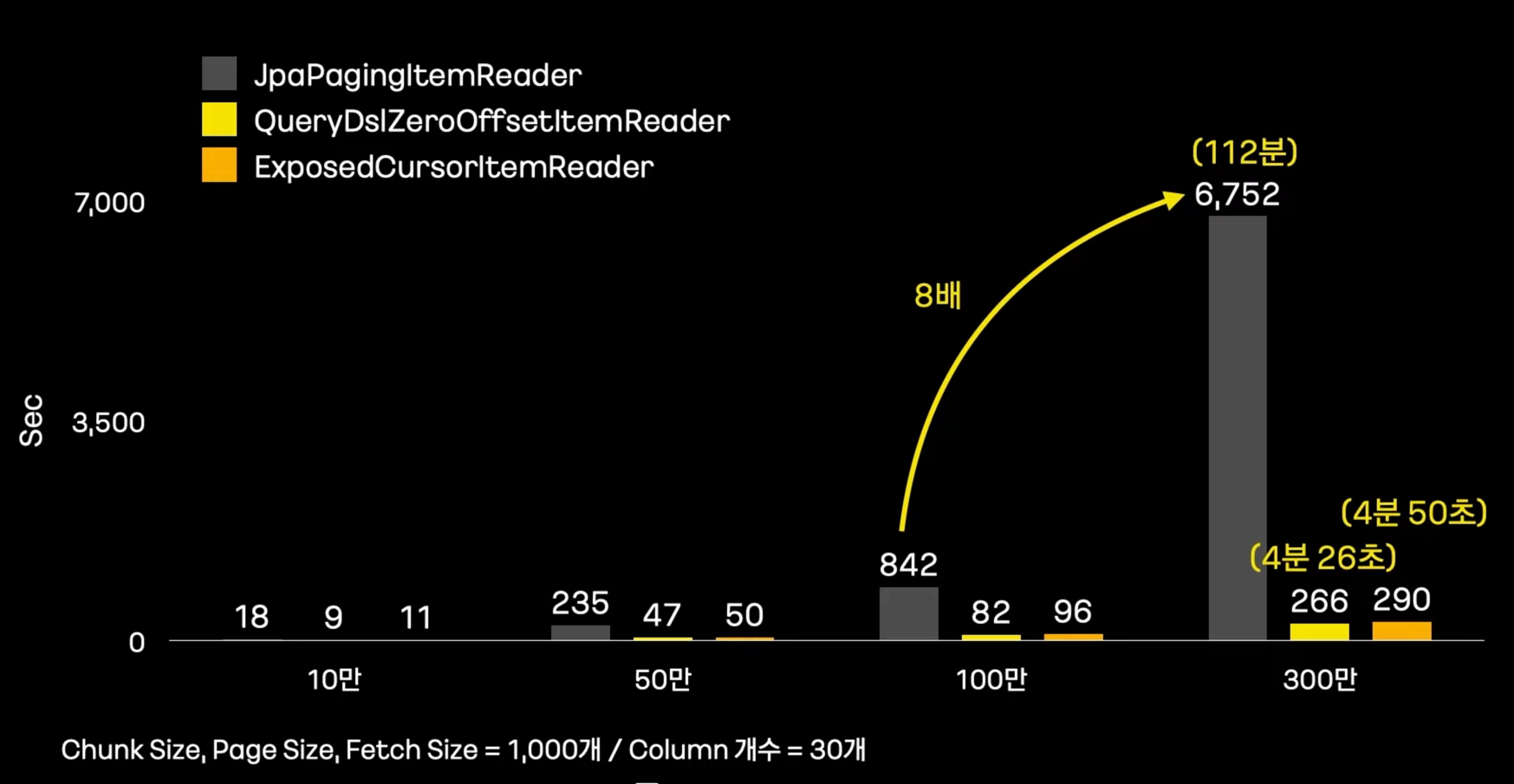
ItemReader 성능 비교
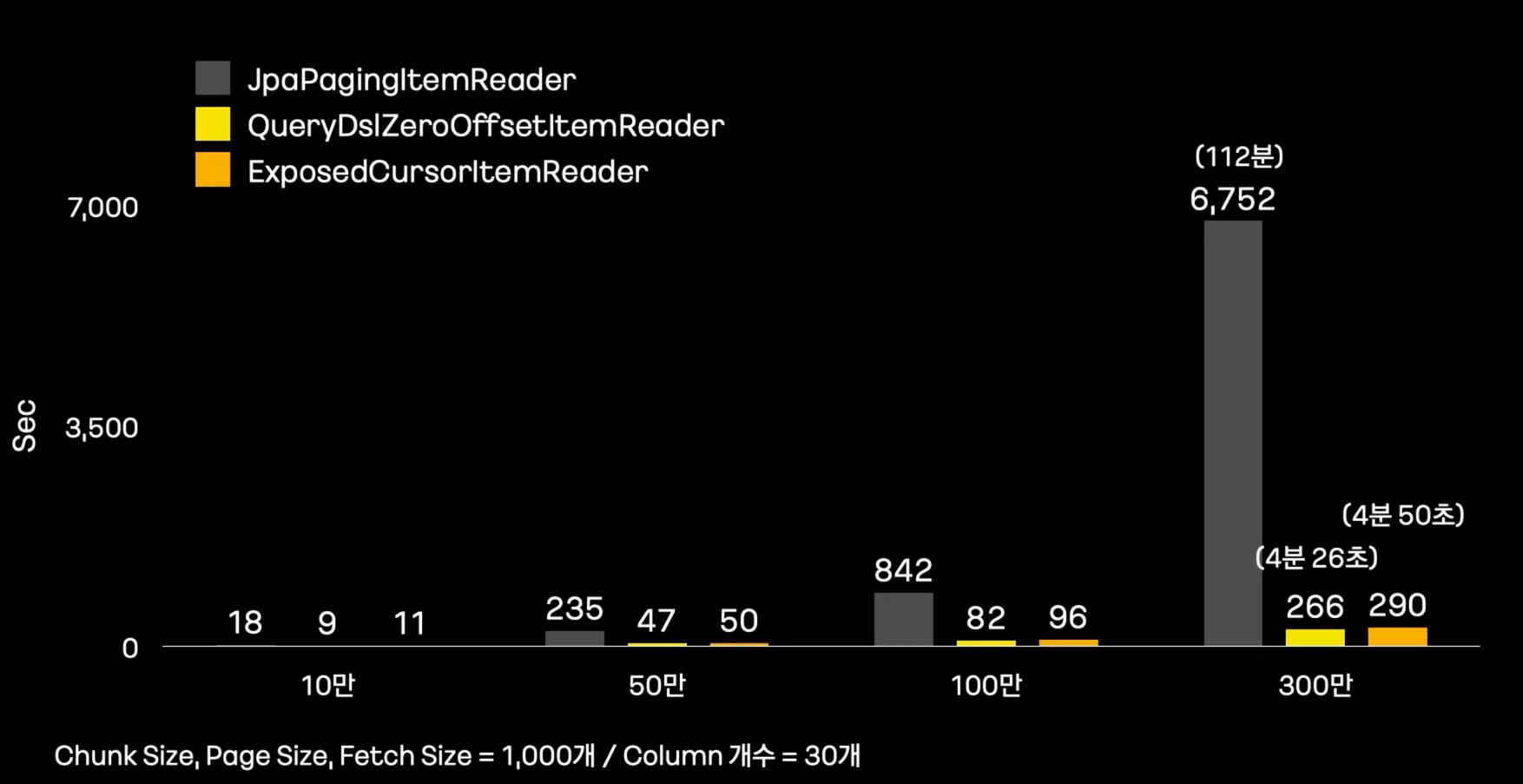
-
데이터가 많아질수록 그 차이는 더 심해진다.
-
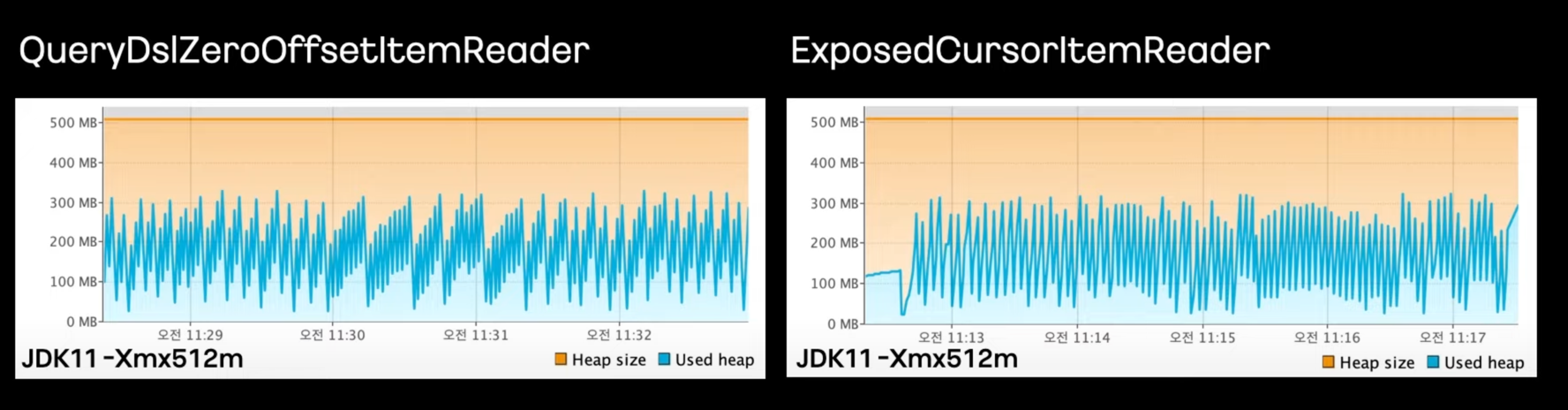
300만건 Heap Space Monitoring
기존의 ItemReader 정리 #

개선한 ItemReader 정리 #

데이터 Aggregation 처리 #
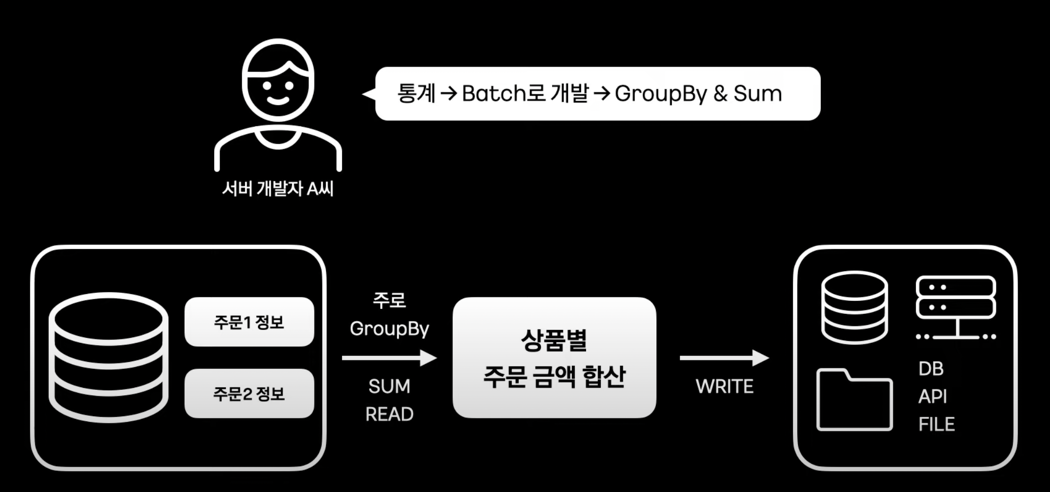
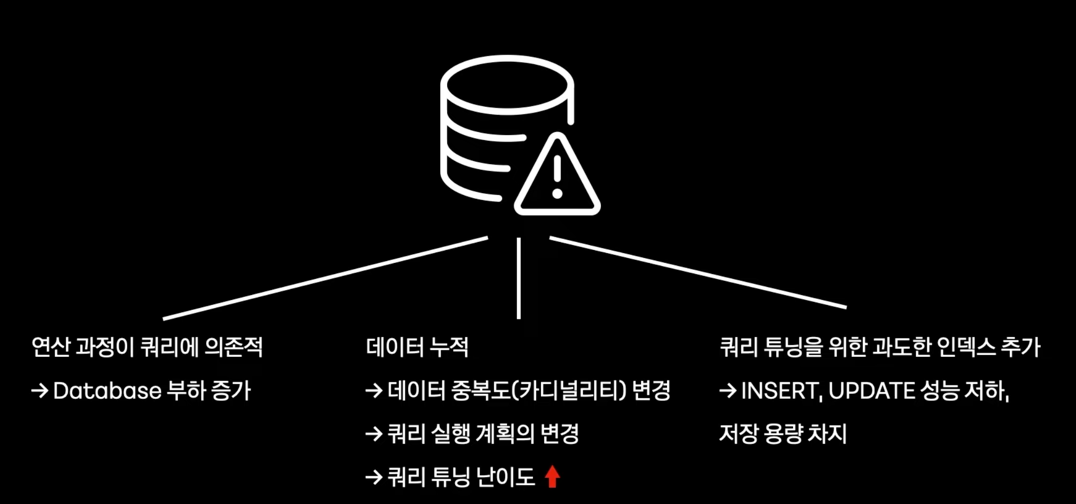
- 데이터가 많아지고 쿼리가 복잡해져도 문제가 없을까?
- SUM 쿼리에 의존하는 배치의 문제점
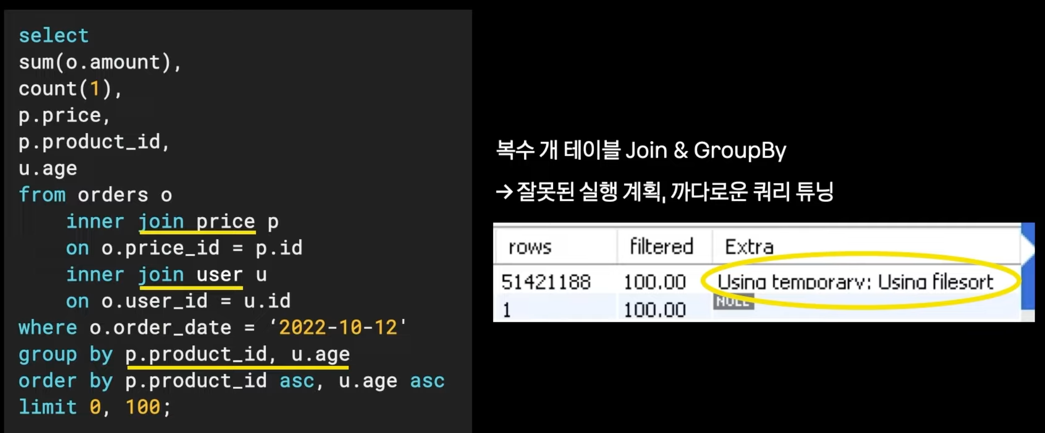
- Join, Groupby, Sum 쿼리를 사용하면 성능 저하
해결 - groupby 를 포기한다. #

- 직접 aggregation을 한다.
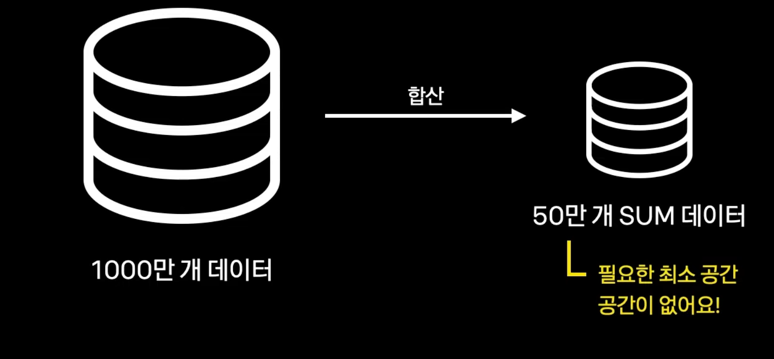
- 1000만개의 데이터를 합산해서 50만개 데이터를 만들때, 최소한 50만개의 데이터 공간이 필요하다.
- OOM 발생 가능성 존재
새로운 Architecture, Redis를 활용한 Sum #
-
충분한 저장공간과 빠른 연산 -> Redis
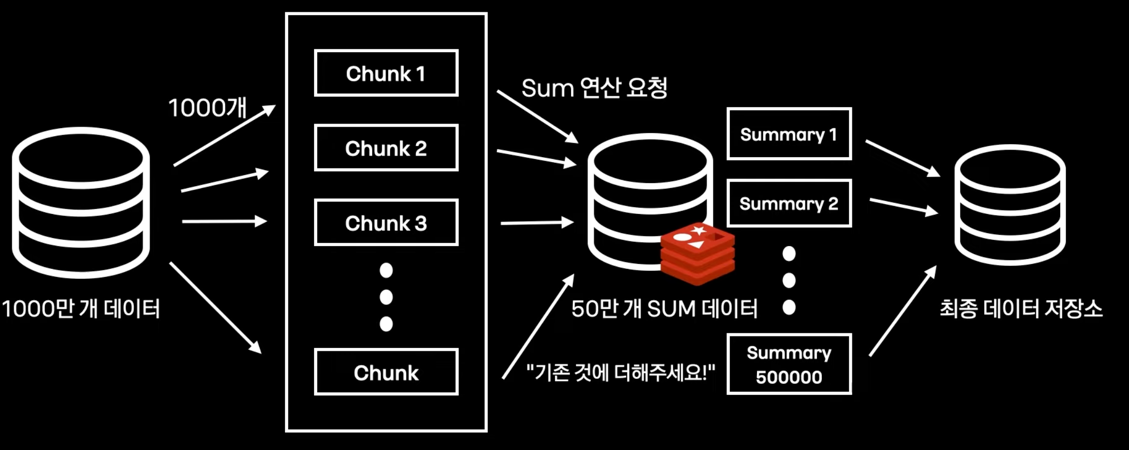
-
Redis를 도입한 이유
- 연산 명령어 (hincrby, hincrbyfloat 지원)
- 메모리 수준에서 합산
- 50만개는 쉽게 저장하는 넉넉한 메모리
- In-Memory DB
- 빠른저장O, 영구저장X
-
해결되지 않은 문제
- 네트워킹 지연성
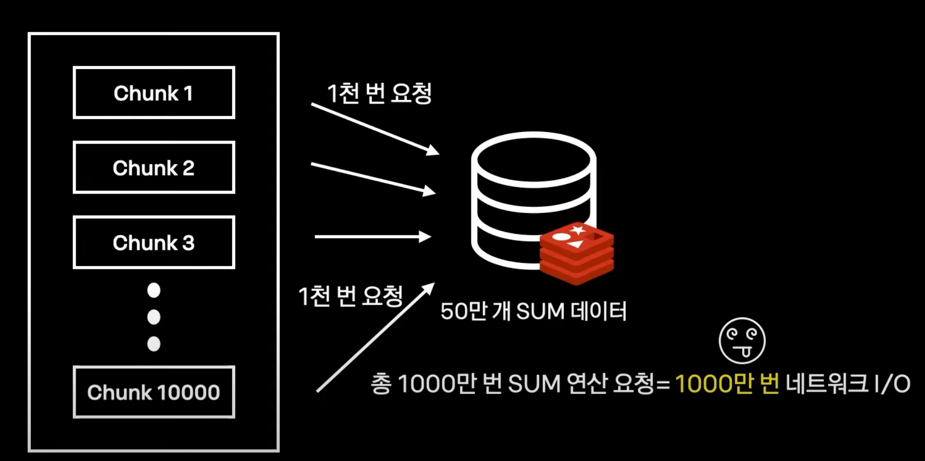
- 전체 성능은 오히려 저하된다.

- 네트워킹 지연성
-
Redis pipeline으로 처리하자.
- 다수 command를 한번에 묶어서 처리한다.
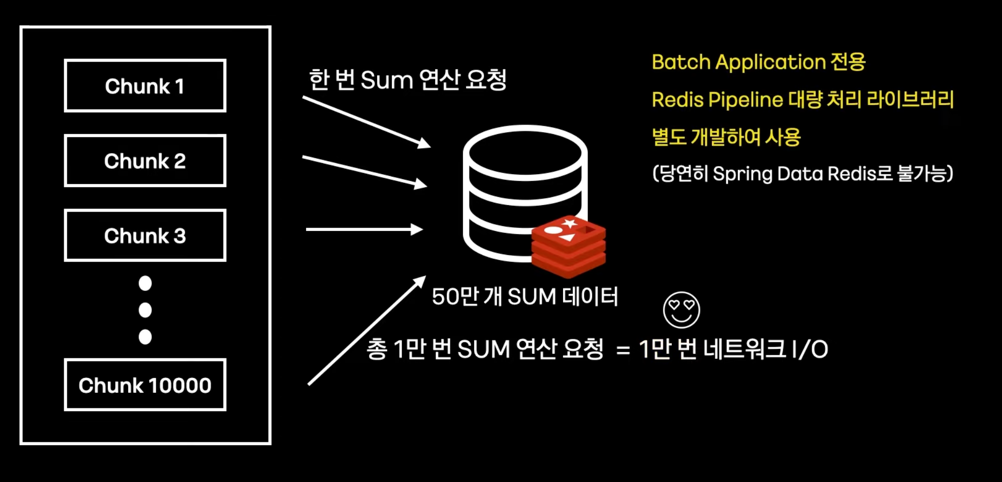
- 다수 command를 한번에 묶어서 처리한다.
대량데이터 Write #

Writer 개선 방법 #
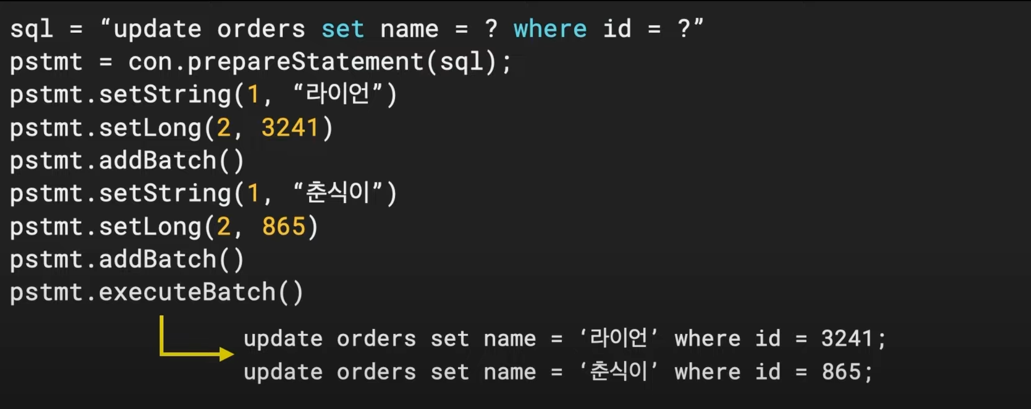
- Batch Insert : 일괄로 쿼리 요청
- 명시적 쿼리 : 필요한 컬러만 Update, 영속성 컨텍스트 사용하지 않기
- JPA를 사용하지 않는다.
- Batch에서 JPA Write에 대한 고찰
- Dirty Checking과 영속성 관리
- 불필요한 check 로직으로 인한 큰 성능 저하
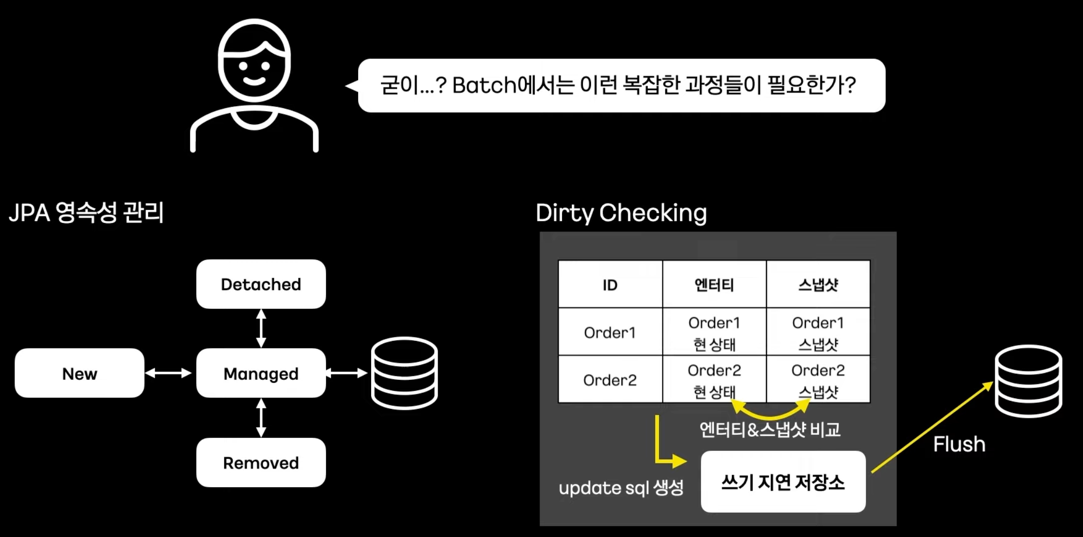
- Read할 때부터 Dirty Checking과 영속성 버리기
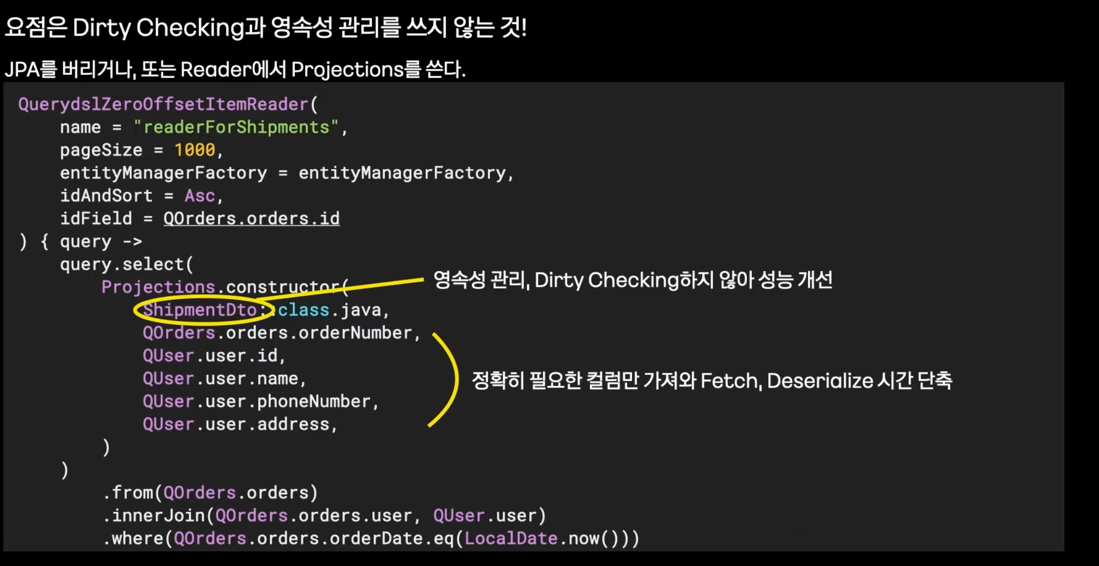
- UPDATE 할때 불필요한 컬럼도 UPDATE
- 불필요한 컬럼 update로 인한 소폭 성능 저하


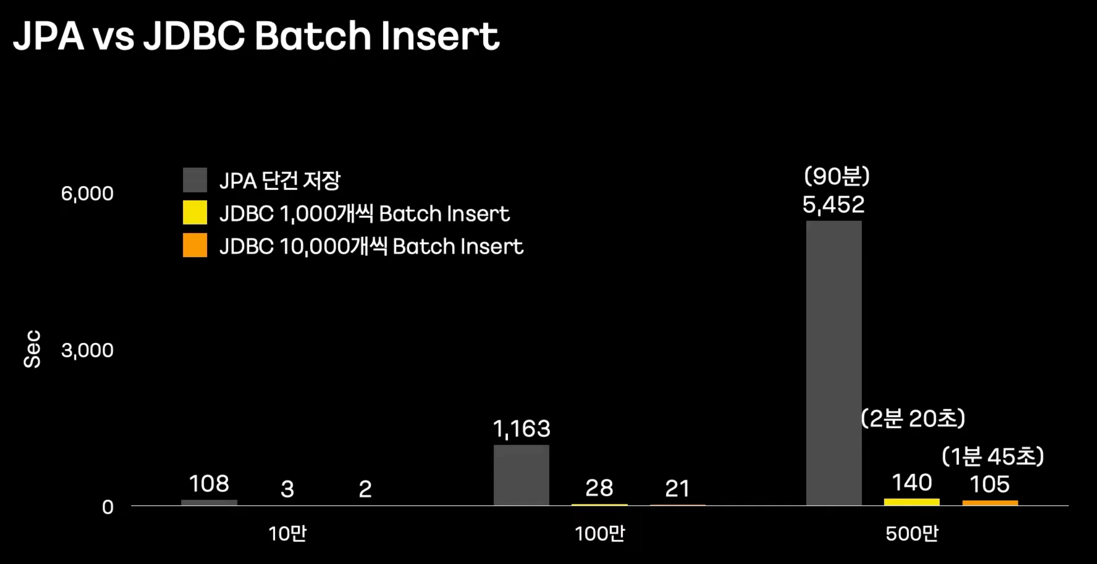
- JPA Batch Insert 지원이 어려운 부분
- batch insert 불가한 경우, 매우 큰 성능 저하

- Batch에서 Batch Insert 사용을 해야한다.
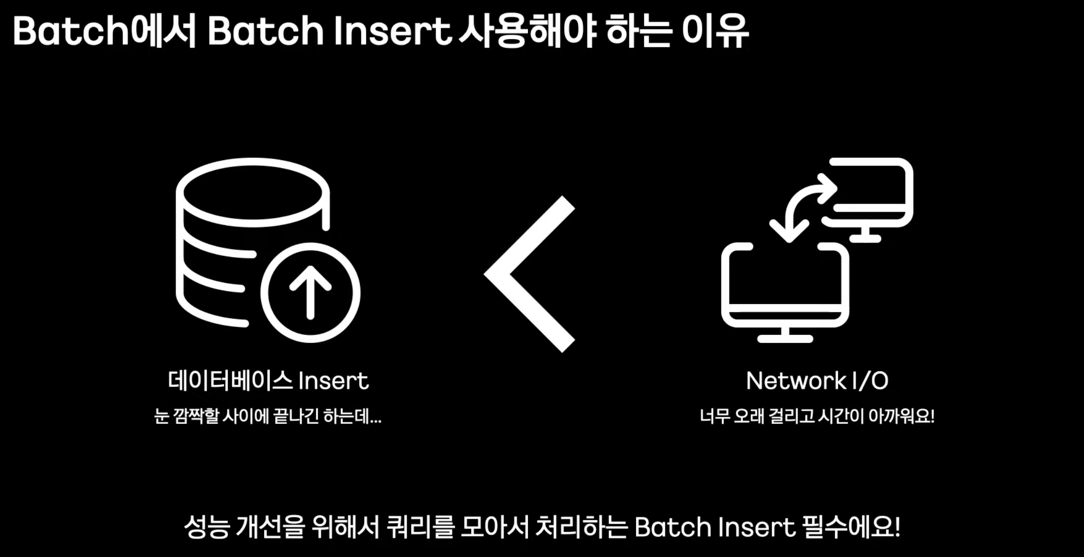
- Batch에서 Batch Insert 사용을 해야한다.
- 결론 : Writer에서 JPA를 포기하고 Batch Insert 할 것
성능 비교 #
Batch 구동 환경 #
- 보통의 환경
- 기존 스케줄 tool의 아쉬운점
-
- 자원관리(Resource Control)의 어려움

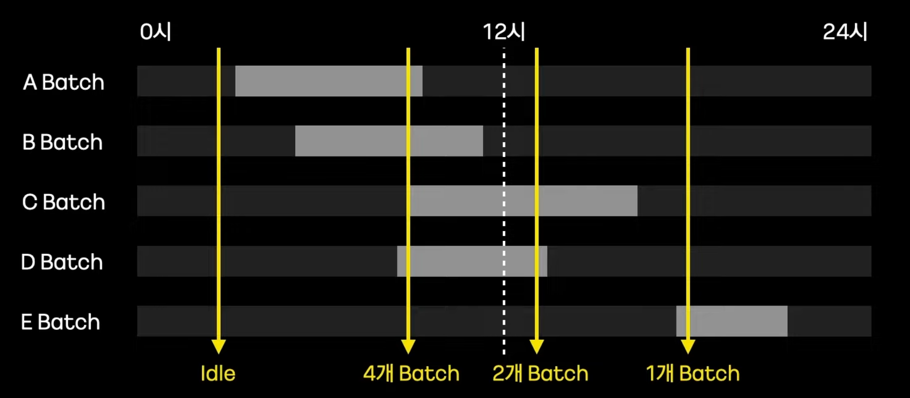
- 자원관리(Resource Control)의 어려움
-
- 배치 상태파악(Monitoring)의 어려움
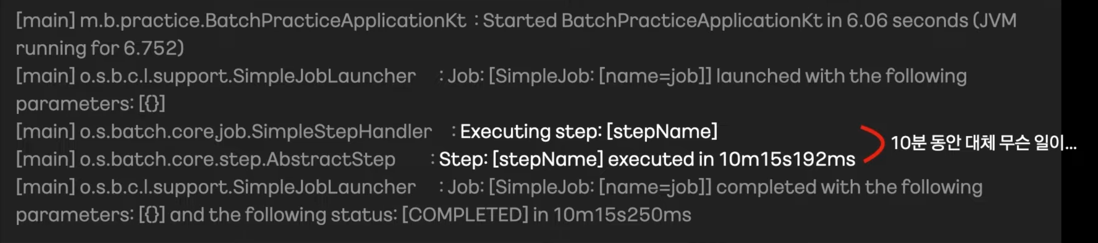
- Batch에서는 동작 하나하나가 매우 길다.
- 대부분 스케줄 Tool에서 로그를 볼 수 있지만 로그가 빈약하다.
- 서비스 상태를 로그로 판단하는것 자체가 전혀 시각적이지 않다.
-
- Spring Cloud Data Flow 도입
Spring Cloud Data Flow #
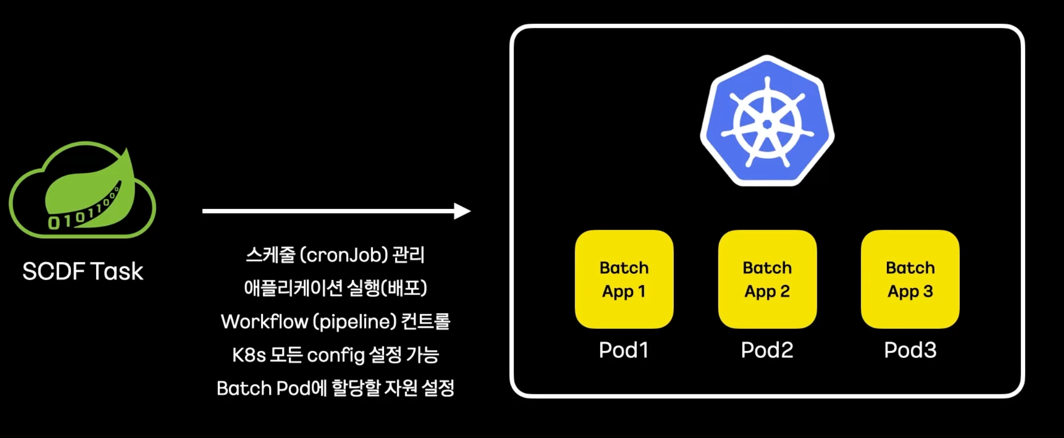
- 데이터 수집, 분석, 데이터 입/출력과 같은 데이터 파이프라인을 만들고 오케스트레이션하는 툴
- 데이터 파이프라인 종류 : Stream, Task(Batch)


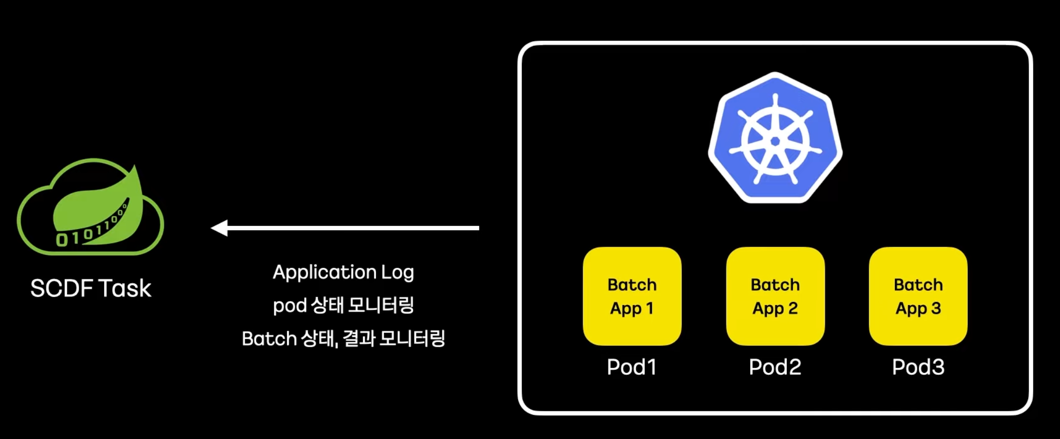
- 동작과 역할
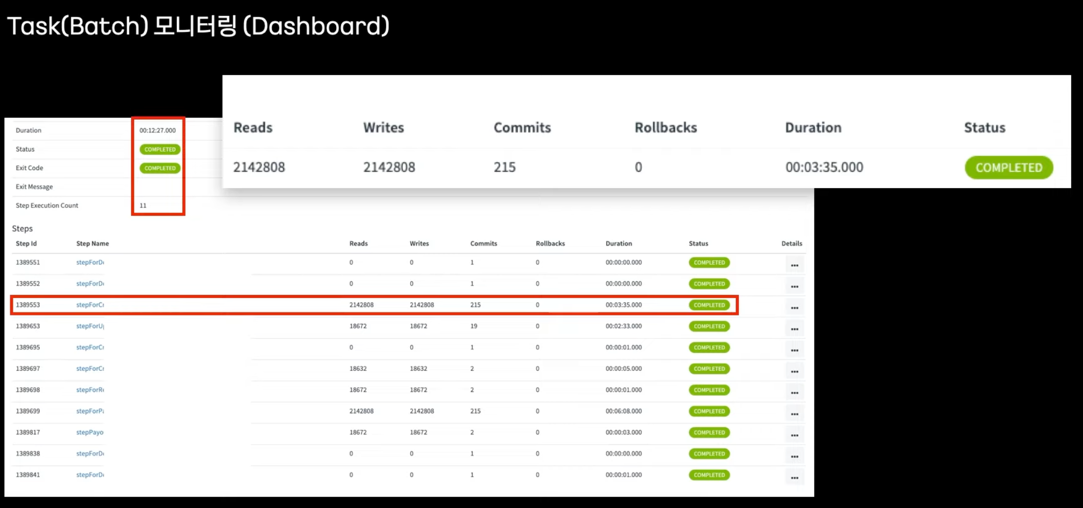
- flow
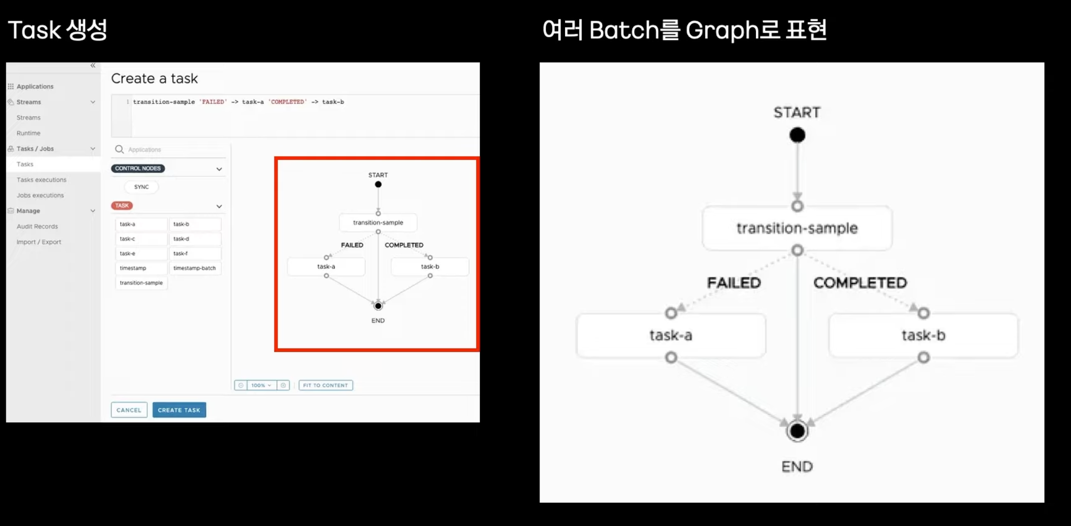
- Task 스케줄 생성
- Monitoring