tech blog 글 읽고 정리하기
#
누구나 할 수 있는 10배 더 빠른 배치 만들기 #
우아한형제들 셀러 시스템 배치 개선 이야기 #
우아한형제들 기술 블로그의 글을 읽으면서 정리해본다.
최근 셀러시스템팀에서 하루 한 번 주기로 실행되는 배치를 최적화하는 과제를 진행한 내용에 대한 포스팅이다.
비운영 시간 데이터 #
- 셀러시스템에서는 가게와 업주에 대한 다양한 데이터를 관리
- 사장님들의 관리 사항
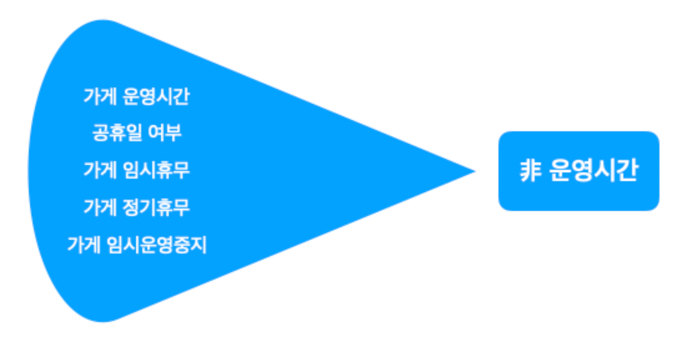
- ‘가게가 운영하는지 안하는지’에 대한 정보를 유관 부서에 전달한다.
- ‘비운영시간 데이터’
- 실시간으로 수정되는 정보를 반영
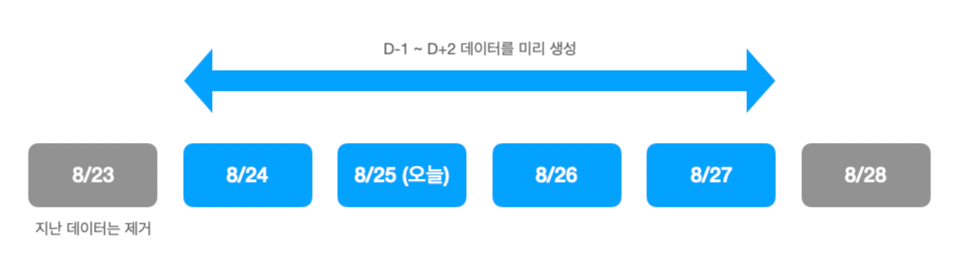
- 매일 새벽에 전체 데이터를 계산하고 그 결과를 미리 갱신해둔 후, 유관부서에 전파
다양한 채널에서 입력되는 각족 운영과 휴무 데이터를 취합해서 비운영시간 데이터를 계산
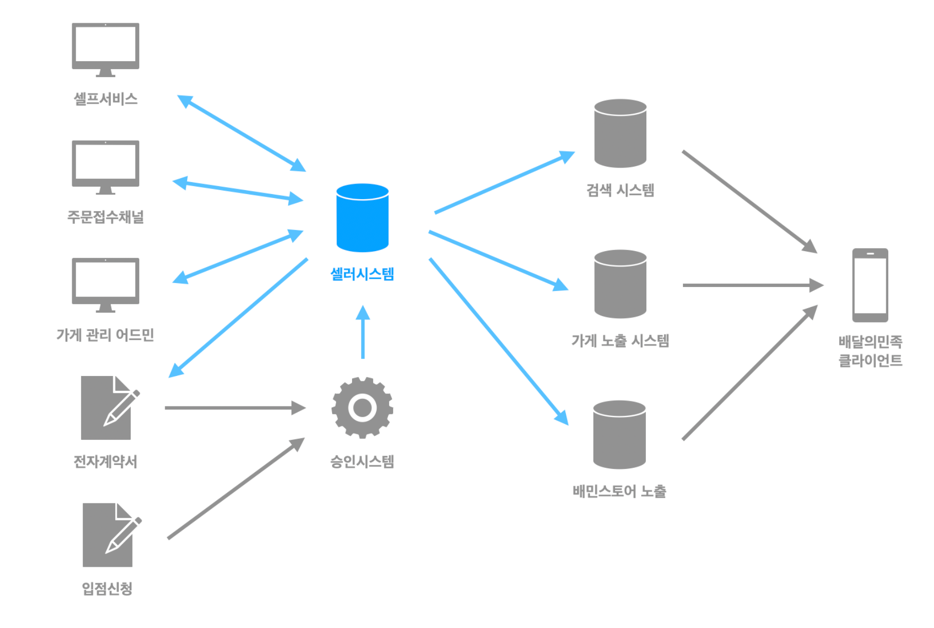
위 계산된 데이터가 클라이언트까지 잘 전달될 수 있도록 각 지면에 적절한 형태로 가공하여 제공
문제상황 #
- 새벽에 배치 작업을 할때, 수많은 가게의 데이터를 매일 갱신하므로 배치 수행시간이 오래걸린다.
- 배포 예정 시간과 배치 실행 시간이 겹칠 경우, 배포가 여러번 복잡한 절차를 밟아 진행해야한다. (잠재적인 리스크)
- 배치 성능 개선이 필요
I/O 최적화 #
- I/O 병목을 먼저 살펴본다.
I/O (Input / Output) 병목이란? 컴퓨팅에서 부하를 설명할 때에는 크게 CPU 부하와 I/O 부하로 나뉩니다. 데이터를 계산하고 처리하는 과정인 CPU 부하와 달리, I/O 부하는 디스크에 파일을 읽고 쓰거나 DB 및 외부 컴포넌트와 통신하는 과정에서 발생합니다. I/O 병목은 이러한 I/O 부하가 시스템의 전체적인 효율성을 떨어뜨리는 부분을 말합니다.
- 배치에서 사용하는 I/O 부하 중 가장 핵심은 DB 쿼리였다.
- 원인 : JPA 지연 로딩으로 설정된 연관 관계 엔티티를 가져오는 과정에서 N+1 문제가 발생
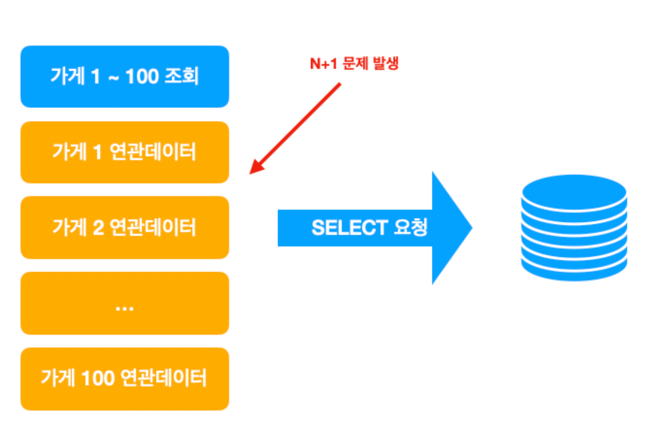
- 데이터가 모두 1:N 구조의 연관관계로 설정되어 있어서 관련 데이터를 가져오는데에 오랜 시간이 걸린다.
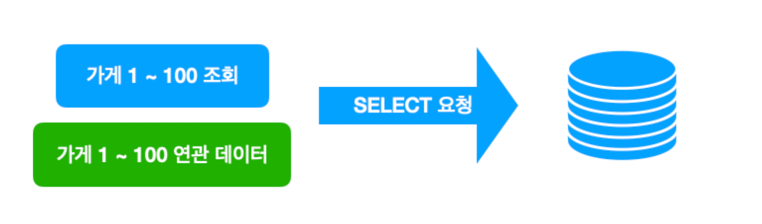
해결
- 연관관계로 설정된 엔티티의 종류가 많고 실제 연관관계 데이터의 수정은 불필요하다는 점 등을 고려하여,
- 각 엔티티 정보를 연관관계를 통해 가져오는 것이 아닌 별도 쿼리 호출을 통해 명시적으로 한 번에 읽어오게끔 수정
Before
public List<LiveShopClose> generateLiveShopClose(Shop shop, LocalDate startDate, LocalDate endDate) {
final List<ShopCalendar> shopCalendars = shopCalendarRepository.findAllByCalendarDateBetween(startDate, endDate);
final List<ShopTemporaryClosed> shopTemporaryCloses = shop.getActiveShopTemporaryClosed();
final List<ShopClosed> shopCloses = shop.getActiveShopClosed();
final List<ShopOperationHour> operationHours = shop.getShopOperationHourIsType(OperationHourType.OPERATION);
return /* LiveShopClose 데이터 생성 */
}
After
List<LiveShopClose> generateLiveShopCloses(List<Long> shopNos, LocalDate startDate, LocalDate endDate) {
List<ShopNo> shopNoEntities = shopNos.stream().map(ShopNo::new).collect(Collectors.toList());
List<ShopCalendar> shopCalendars = shopCalendarRepository.findAllByCalendarDateBetween(startDate, endDate);
Map<Long, List<ShopTemporaryClosed>> activeShopTemporaryClosedMap =
shopTemporaryClosedRepository.findActiveByShopNos(shopNoEntities).stream()
.collect(groupingBy(ShopTemporaryClosed::getShopNo, Collectors.toList()));
Map<Long, List<ShopClosed>> activeShopClosedMap =
shopClosedRepository.findActiveByShopNos(shopNoEntities).stream()
.collect(groupingBy(ShopClosed::getShopNo, Collectors.toList()));
Map<Long, List<ShopOperationHour>> operationHoursMap =
shopOperationHoursRepository.findOperationHoursByShopNos(shopNoEntities).stream()
.collect(groupingBy(ShopOperationHour::getShopNo, Collectors.toList()));
return shopNos.stream()
.flatMap(shopNo -> generateLiveShopClose(
shopNo,
shopCalendars,
ListUtils.emptyIfNull(activeShopTemporaryClosedMap.get(shopNo)),
ListUtils.emptyIfNull(activeShopClosedMap.get(shopNo)),
ListUtils.emptyIfNull(operationHoursMap.get(shopNo))
).stream())
.collect(Collectors.toList());
}
List<LiveShopClose> generateLiveShopClose(Long shopNo, List<ShopCalendar> shopCalendars,
List<ShopTemporaryClosed> activeShopTemporaryCloses,
List<ShopClosed> activeShopCloses,
List<ShopOperationHour> operationHours) {
return /* LiveShopClose 데이터 생성 */
}
도메인 로직 및 기타 최적화 #
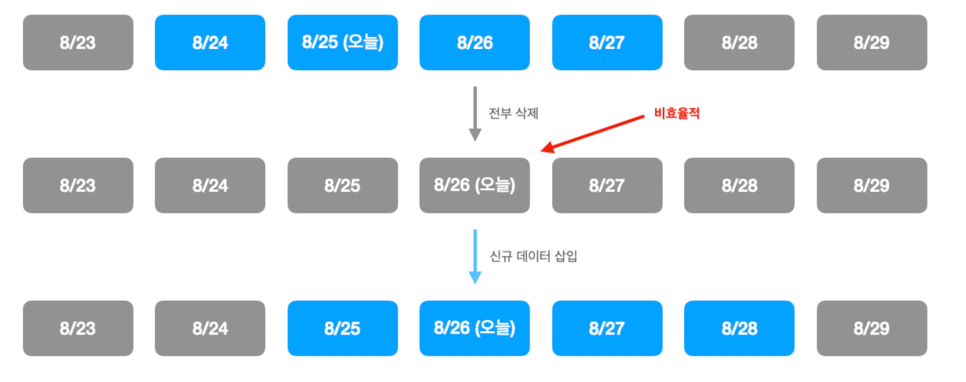
- 현재 가게의 비운영시간 데이터가 업데이트될 경우, 변경된 가게에 대한 이벤트를 발행
- 기존 로직에서는 실제 데이터의 변경 여부와는 관계없이 D-1~D+2 데이터를 무조건 재생성하기 때문에,
- 실제로는 데이터가 변경되지 않을 테지만 다시 데이터가 생성되어 변경 이벤트가 전송되는 케이스 존재
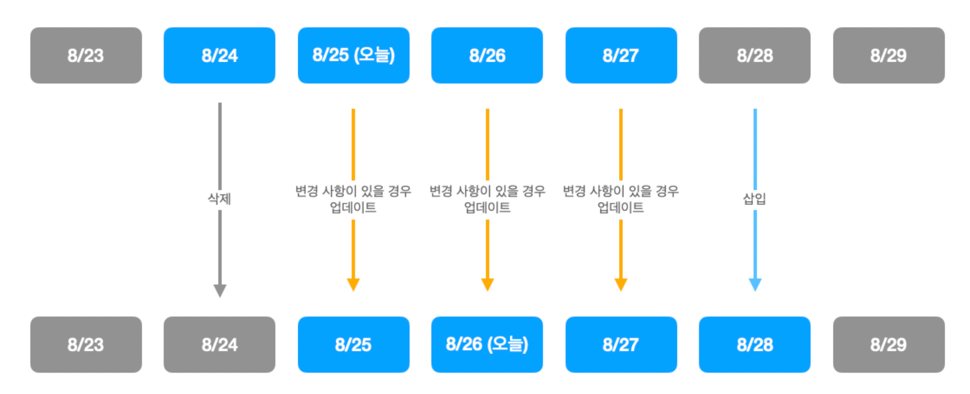
- 대응 : 이러한 케이스에 대응하여 데이터가 바뀌었는지 여부를 확인한 후 실제로 바뀐 경우에만 변경 사항을 적용
- 효과 : 변경 이벤트로 인한 간접적인 부하 개선
최적화 검토 #
- 성능 효율을 높이기 위해 컴퓨팅 업계에서는 많은 죄악이 저질러지는데(심지어 효율적이지조차 않을 때도 있다) 그 수는 그냥 멍청해서 저지르는 죄악보다 많다.
- William A. Wulf (1972)
- 우리는 세세한 성능 효율에 대해서는 무시할 필요가 있다. 말하자면 97%가 이 경우에 해당한다. 섣부른 최적화는 만악의 근원이다.
- Donald E. Knuth (1974)
- 우리는 최적화에 대해서 다음 두가지 규칙을 따른다. 첫째. 하지 마라. 둘째. (전문가 한정) 아직은 하지 마라. 최적화되지 않은 상태로도 완벽하게 깔끔한 해결책을 찾는 것이 먼저다.
- M. A. Jackson (1975)
효율만 쫒다가 득보다 실이 큰 경우를 경계하라는 뜻
최적화를 하기 전에 항상 아래 두가지를 검토
-
최적화 이전에 먼저 좋은 코드를 작성하기 코드를 작성하는 데 있어서 성능을 염두에 두는 것은 물론 중요합니다. 하지만 많은 경우 대부분의 코드는 성능상 영향이 크지 않고 실제로 병목이 되는 부분은 극히 일부분입니다. 좋은 코드를 최적화하기는 쉽지만, 섣부르게 최적화된 코드를 좋은 코드로 만드는 건 어렵습니다. 빠른 코드보다는 좋은 코드를 짜는 데에 먼저 집중하고 최적화는 그 다음에 생각해야 합니다.
-
정량적으로 성능을 측정하면서 병목을 파악하기 정량화된 지표를 통해 실제로 병목이 되는 부분을 파악해야 합니다. 지엽적인 부분을 일일히 개선하는 마이크로 최적화는 많은 경우 100ms 를 99ms로 줄이는 것에 그칩니다. 마이크로 최적화 보다는 거시적인 관점에서 중요한 병목을 찾고 이를 구조적으로 해결하는 것이 중요합니다. 그리고 실질적으로 얼마나 빨라졌는지 정량적인 성과로 나타낼 수 있어야 합니다.
검토해야할 부분 #
위 개선을 통해 배치 수행시간이 너무 빨라졌다.
MSA 구조에서는 애플리케이션과 직접적으로 연동되는 DB와 로드밸런서 뿐만 아니라,
많은 모듈 및 유관부서들이 유기적으로 연결되어있기 때문에 영향 범위를 면밀히 검토해야한다.

-
데이터 변경이 발생하면 변경 사항이 큐를 통해서 유관 부서에 전달된다.
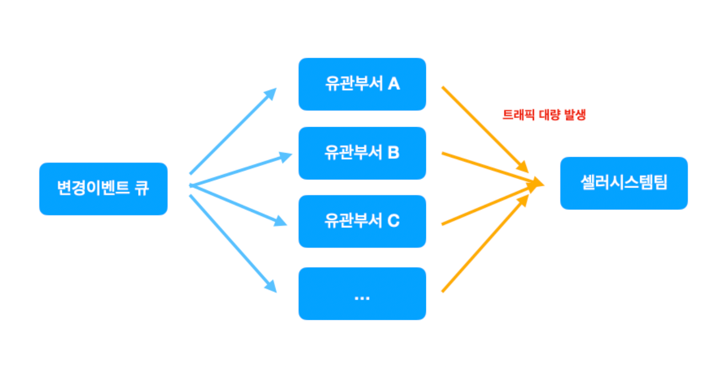
-
확인 지표
- 개발 환경에서 테스트 당시 애플리케이션이 실행되는 서버의 CPU 및 I/O 지표
- 개발 환경에서 테스트 당시 DB CPU, 쿼리 지연 시간 등 지표
- 예상 트래픽을 산출, 현재 운영 환경에서의 피크 트래픽과 비교하여 문제가 없을지 검토
- 변경 사항을 전달하는 큐에서 지연이 발생해도 문제가 없을지 검토
너무 빨라도 문제 #
- 빠르게 동작하기 때문에, 유관 부서 트래픽 또한 예상 이상으로 인입되어 DB CPU가 높아짐
해결방안 : 의도적으로 지연 시간 설정
@Bean(STEP_NAME)
@JobScope
public Step liveShopCloseCreateStep() {
return stepBuilderFactory.get(STEP_NAME)
.<Long, Long>chunk(CHUNK_SIZE)
.reader(shopCloseScheduleReader(null))
.writer(liveShopCloseWriter(null, null, null))
.transactionManager(storeTransactionManager)
.listener(new AfterChunkSleepListener(200))
.build();
}
@Slf4j
public class AfterChunkSleepListener implements ChunkListener {
private final long sleepMillis;
public AfterChunkSleepListener(long sleepMillis) {
this.sleepMillis = sleepMillis;
}
@Override
public void afterChunk(ChunkContext context) {
try {
log.info("Chunk 실행 후 sleep {} millis. 현재 read Count : {}",
sleepMillis,
context.getStepContext().getStepExecution().getReadCount());
TimeUnit.MILLISECONDS.sleep(sleepMillis);
} catch (InterruptedException e) {
log.error("Thread sleep interrupted.", e);
}
}
@Override
public void afterChunkError(ChunkContext context) {
// 사용안함.
}
@Override
public void beforeChunk(ChunkContext context) {
// 사용안함.
}
}
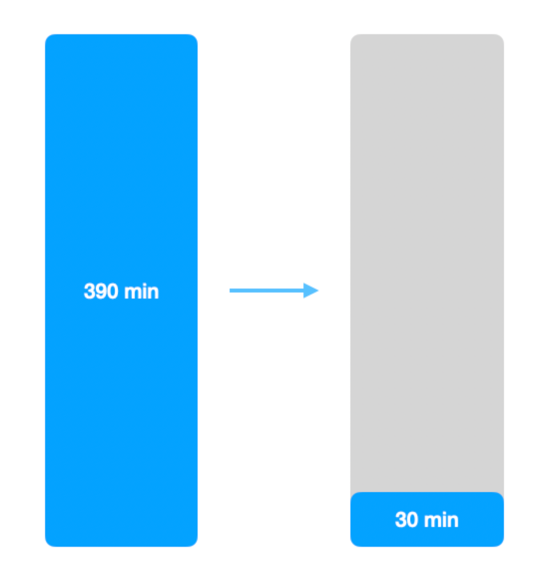
- 지연 시간을 설정해도 배치는 390분 -> 30분 소요되는 결과를 얻음
최적화 작업 #
- 리스크를 확인하고 과제에 대한 우선순위를 조정하기
- 문제 상황을 분석하고 병목을 확인하기
- I/O의 경우 최대한 한번에 여러건을 읽고 쓰도록 하여 효율성 높이기
- 도메인 로직을 검토하여 개선할 수 있는 부분이 있는지 살피기
- 유의미한 최적화인가? 정량적인 지표로 다시 검토하기
- 빨라도 문제일 수 있으니 최적화에 의한 영향 범위를 검토하고 운영 환경에서도 문제가 없을지 확인하기
참고 #
- 위 배치의 chunk size : 100으로 설정